











Der Übergang von traditionellen on-premises-Infrastrukturen zu cloud-nativen Umgebungen stellt eine grundlegende Veränderung dar, wie Daten gespeichert, abgerufen und verwaltet werden. Für Datenbankadministratoren (DBAs) erfordert dieser Übergang mehr als nur das Migrieren bestehender Schemata. Es erfordert eine Neubewertung von Entitäts-Beziehungs-Diagrammen (ERDs), um mit den einzigartigen Beschränkungen und Möglichkeiten verteilter Systeme übereinzustimmen. Dieser Leitfaden bietet einen umfassenden Überblick über das Entwerfen von ER-Diagrammen, die Skalierbarkeit, Widerstandsfähigkeit und Leistungsfähigkeit in modernen Cloud-Architekturen unterstützen. 📊
Verständnis der Veränderung in der Datenarchitektur 🔄
Traditionelles Datenbankdesign legt oft Wert auf strenge Normalisierung und zentrale Steuerung. Im Gegensatz dazu betonen cloud-native Architekturen Verfügbarkeit, Partitions-Toleranz und horizontales Skalieren. Der zentrale Unterschied liegt in der Annahme von Fehlern. In einer monolithischen Umgebung ist die Datenbank ein einziger Fehlerpunkt. In einer cloud-nativen Umgebung fallen Knoten häufig aus, und das System muss sofort darauf reagieren.
Beim Entwerfen von ER-Diagrammen für diese Umgebung müssen DBAs folgendes berücksichtigen:
- Verteilte Konsistenz:Wie halten Beziehungen stand, wenn Daten über Regionen verteilt sind?
- Latenz:Wie beeinflusst die physische Entfernung zwischen Datenknoten die Abfrageleistung?
- Kosten:Was ist der Kompromiss zwischen Speicherredundanz und Transaktionskosten?
- Betriebliche Komplexität:Kann das Schema ohne ständige manuelle Eingriffe verwaltet werden?
Das Ignorieren dieser Faktoren kann zu Systemen führen, die schwer zu skalieren oder zu pflegen sind. Ein gut gestaltetes ER-Diagramm fungiert als Bauplan für den Datenfluss und stellt sicher, dass die zugrundeliegende Infrastruktur die Geschäftslogik ohne Engpässe unterstützen kann. 🚀
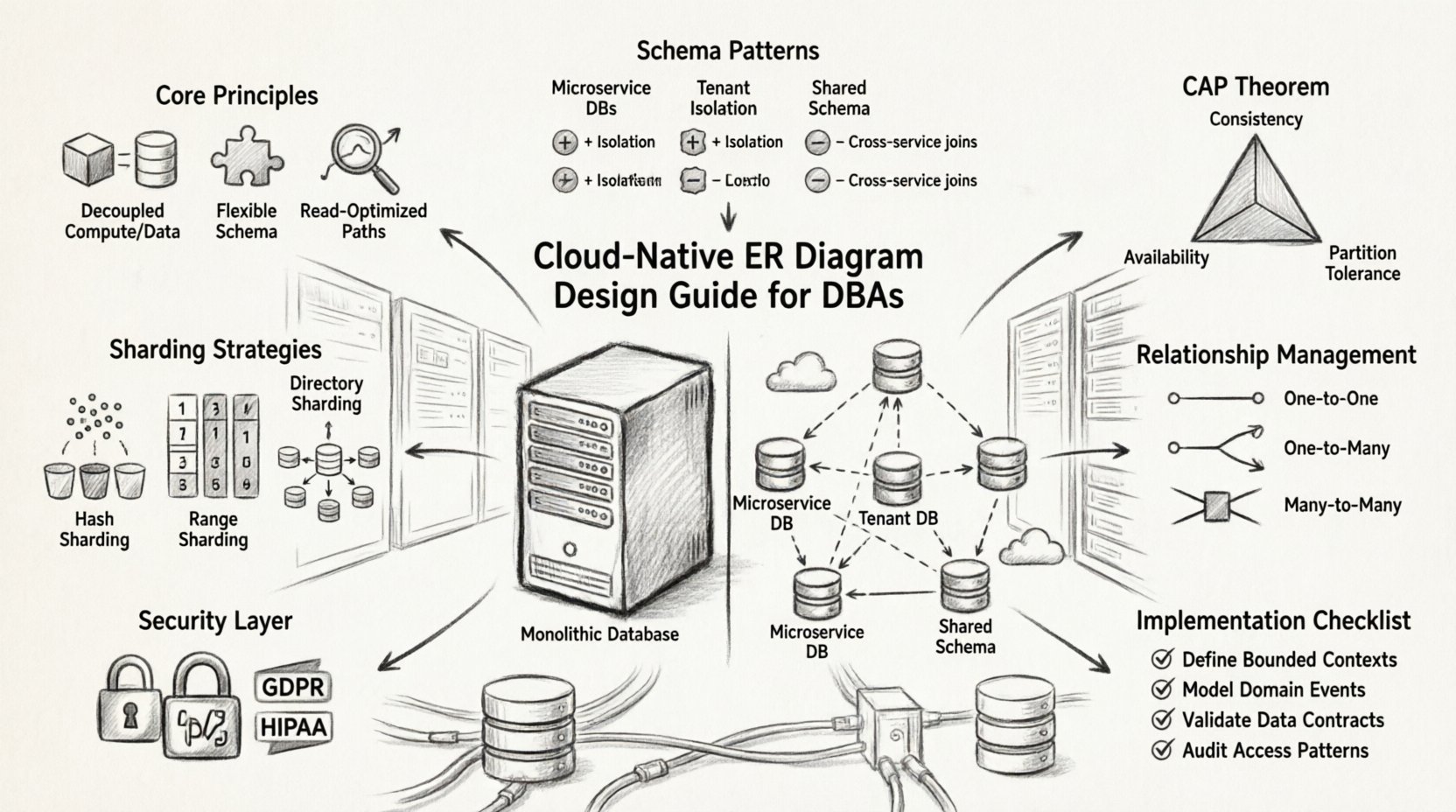
Grundprinzipien von cloud-nativen ERDs ⚙️
Bevor man sich spezifischen Mustern widmet, ist es unerlässlich, die Leitprinzipien zu verstehen, die die cloud-native Datenmodellierung von traditionellen Ansätzen unterscheidet.
1. Entkopplung von Daten und Rechenleistung
In vielen Legacy-Systemen sind der Datenbankserver und der Anwendungsserver eng gekoppelt. Cloud-native Design trennt diese Aspekte. Das ERD sollte dies widerspiegeln, indem Abhängigkeiten minimiert werden, die eine synchrone Kommunikation zwischen unterschiedlichen Diensten erfordern.
2. Akzeptanz von Schema-Flexibilität
Während SQL-Datenbanken starr sind, nutzen cloud-native Umgebungen oft polyglotte Persistenz. Das bedeutet, dass unterschiedliche Datentypen unterschiedliche Speichermodelle erfordern können. Das ER-Diagramm sollte logische Beziehungen visualisieren, auch wenn die physischen Implementierungen variieren (z. B. JSON-Speicher neben relationalen Tabellen).
3. Optimierung für Lese-lastige Workloads
Cloud-Anwendungen versorgen oft Millionen von Nutzern gleichzeitig. Das ER-Design muss effiziente Lesepfade unterstützen, auch wenn dies eine gewisse Redundanz erfordert. Die Denormalisierung wird zu einem strategischen Werkzeug, statt zu einer Sünde.
Schema-Entwurfsmuster für Skalierbarkeit 📈
Die Auswahl des richtigen Schemamusters ist entscheidend für die Leistung. Nachfolgend finden Sie gängige Ansätze, die in verteilten Systemen verwendet werden.
Einzelne Datenbank pro Dienst
Jeder Microservice verwaltet sein eigenes Datenbankschema. Diese Isolation verhindert, dass Dienstausfälle sich ausbreiten. Das ER-Diagramm für das Gesamtsystem wird zu einer Sammlung kleiner, unabhängiger Diagramme, die durch logische Referenzen verbunden sind.
Geteilte Datenbank mit Schematrennung
Mehrere Dienste teilen sich eine einzelne Datenbankinstanz, halten aber separate Schemanamensräume aufrecht. Dies reduziert die Infrastrukturkosten, bringt aber Risiken einer engen Kopplung mit sich. Es wird im Allgemeinen für großskalige Cloud-Implementierungen abgeraten.
Datenbank pro Mandant
Bei mehrfach nutzenden SaaS-Anwendungen erhält jeder Kunde eine dedizierte Datenbankinstanz. Das ERD-Design muss über alle Instanzen hinweg konsistent bleiben, um sicherzustellen, dass Migrationen und Aktualisierungen einheitlich angewendet werden.
Vergleich von Schemamustern
| Muster | Vorteile | Nachteile | Beste Einsatzmöglichkeit |
|---|---|---|---|
| Einzelne Datenbank | Einfache Joins, ACID-Konformität | Einzelner Ausfallpunkt, Skalierungsgrenzen | Monolithische Anwendungen, geringer Datenverkehr |
| Datenbank pro Dienst | Unabhängige Skalierung, Fehlerisolierung | Komplexe Transaktionen, verteilte Joins | Mikrodienste, hoher Wachstum |
| Datenbank pro Mandant | Datenisolation, vereinfachte Compliance | Hohe Infrastrukturkosten, Verwaltungsaufwand | SaaS-Plattformen, regulierte Branchen |
| Geteiltes Schema | Niedrige Kosten, gemeinsame Abfragen | Vendor-Abhängigkeit, Skalierungsengpässe | Interne Tools, MVPs |
Verwaltung von Beziehungen zwischen Diensten 🔗
In einer verteilten Architektur sind Fremdschlüssel nicht immer durchführbar. Die Referenzintegrität muss anders verwaltet werden. Das ER-Diagramm sollte diese logischen Beziehungen klar darstellen, auch wenn die physische Durchsetzung auf der Anwendungsebene oder über asynchrone Prozesse erfolgt.
Arten von Beziehungen
- Ein-zu-Eins:Oft wird dies durch direktes Einbetten von Daten bewältigt, um die Join-Latenz zu reduzieren.
- Ein-zu-Viele: Erfordert sorgfältige Überlegung darüber, wie die Kind-Records gespeichert werden. Wenn der Elternsatz verschoben wird, werden dann auch die Kinder mitverschoben?
- Viele-zu-Viele: Typischerweise wird dies über eine Assoziations-Tabelle implementiert. In Cloud-Umgebungen könnte diese Tabelle unabhängig shardet werden müssen.
Behandlung der Referenziellen Integrität
Ohne strenge Fremdschlüsselbeschränkungen beruht die Datenkonsistenz auf der Anwendungslogik. Strategien umfassen:
- Weiche Löschungen:Markieren von Datensätzen als inaktiv anstatt sie zu entfernen, um die Historie zu bewahren.
- Eventuelle Konsistenz:Verwenden von Ereignisströmen, um Änderungen über Dienste hinweg zu verbreiten.
- Kompensierende Transaktionen:Rückgängigmachungslogik, die Fehler in verteilten Workflows behandelt.
Partitionierungs- und Sharding-Strategien 🗂️
Wenn das Datenvolumen wächst, kann ein einzelner Datenbankknoten die Last nicht mehr bewältigen. Die Partitionierung (Sharding) teilt die Daten auf mehrere Knoten auf. Das ER-Diagramm muss anzeigen, wie die Daten verteilt werden, um Hotspots zu vermeiden.
Sharding-Schlüssel
Die Wahl des Sharding-Schlüssels bestimmt, wie Abfragen weitergeleitet werden. Ein guter Schlüssel verteilt die Daten gleichmäßig und entspricht den Zugriffsmustern.
- Hash-basiert:Verteilt die Daten zufällig. Gut für gleichmäßigen Zugriff, schlecht für Bereichsabfragen.
- Bereichsbasiert:Teilt die Daten nach Wert auf (z. B. Daten oder IDs). Gut für Bereichsabfragen, birgt das Risiko einer ungleichmäßigen Verteilung.
- Verzeichnisbasiert:Wartet einen Abbildungsdienst, um Daten zu lokalisieren. Fügt Latenz hinzu, ermöglicht aber flexible Platzierung.
Auswirkungen auf ER-Diagramme
Beim Entwurf des ERD ist zu beachten, dass:
- Tabellen, die häufig verbunden werden, sollten idealerweise gemeinsam lokalisiert werden, um den Netzwerkverkehr zu minimieren.
- Globale Tabellen (wie Konfigurationsdaten) sollten ungeschachtelt bleiben.
- Indizes müssen so gestaltet werden, dass sie innerhalb der Shard-Grenzen funktionieren.
Konsistenzmodelle und CAP-Theorem ⚖️
Das CAP-Theorem besagt, dass ein verteiltes System nur zwei der drei Eigenschaften garantieren kann: Konsistenz, Verfügbarkeit und Partitionstoleranz. Cloud-native Systeme setzen auf Partitionstoleranz, was eine Wahl zwischen Konsistenz und Verfügbarkeit erzwingt.
Die richtige Modellwahl
| Modell | Beschreibung | Auswirkung auf das ERD |
|---|---|---|
| Starke Konsistenz | Alle Knoten sehen dieselben Daten zur gleichen Zeit | Erfordert synchrone Schreibvorgänge; begrenzt die Schreibdurchsatzleistung |
| Eventuelle Konsistenz | Daten werden nach einer Verzögerung konsistent | Erlaubt asynchrone Schreibvorgänge; erfordert die Behandlung veralteter Lesevorgänge |
| Kausale Konsistenz | Erhält die Reihenfolge kausal verbundener Operationen | Komplexes Verfolgen von Abhängigkeiten im ERD |
Für Finanzanwendungen ist eine starke Konsistenz oft notwendig. Für soziale Feeds ist die eventuelle Konsistenz akzeptabel. Das ER-Diagramm sollte annotieren, welche Tabellen eine strenge Reihenfolge erfordern und welche Verzögerungen tolerieren können.
Indizierung für Umgebungen mit hoher Durchsatzleistung 🏷️
Indizierungsstrategien in der Cloud unterscheiden sich aufgrund von Speicherkosten und Netzwerkbandbreite von lokalen Lösungen. Jeder Index verbraucht Schreibressourcen und Speicherplatz.
Best Practices für die Indizierung
- Minimieren Sie sekundäre Indizes: Indizieren Sie nur Spalten, die in häufigen Abfrageprädikaten verwendet werden.
- Berücksichtigen Sie abdeckende Indizes: Fügen Sie alle erforderlichen Spalten in den Index ein, um Tabellenabfragen zu vermeiden.
- Überwachen Sie die Indizierungsnutzung: Führen Sie regelmäßig Audits der Indizierungsleistung durch, um nicht verwendete Strukturen zu entfernen.
- Gepartitionierte Indizes: Richten Sie die Indexstruktur an der Datenpartitionsstrategie aus.
Globale vs. lokale Indizes
Globale Indizes erstrecken sich über alle Shards und können teuer zu pflegen sein. Lokale Indizes befinden sich innerhalb eines Shards und sind kostengünstiger. Beim Entwurf des ERD sollten Sie angeben, welche Indizes global und welche lokal sind, um das Infrastrukturteam zu unterstützen.
Sicherheits- und Compliance-Betrachtungen 🛡️
Datensicherheit in der Cloud umfasst Verschlüsselung, Zugriffssteuerung und die Einhaltung von Vorschriften wie DSGVO oder HIPAA. Das ER-Diagramm sollte die Datensensibilitätsstufen widerspiegeln.
Dateneinstufung
Markieren Sie Dateneinheiten basierend auf der Sensibilität:
- Öffentlich: Kein besonderer Schutz erforderlich.
- Intern: Nur für Mitarbeiter zugänglich.
- Eingeschränkt: Erfordert Verschlüsselung und strenge Zugriffsprotokollierung.
Verschlüsselung ruhender und übertragener Daten
Alle sensiblen Felder sollten zur Verschlüsselung markiert werden. Das ERD sollte keine unverschlüsselten sensiblen Daten speichern. Stattdessen sollte es auf verschlüsselte Spalten oder Tokens verweisen.
Compliance und Aufbewahrung
Einige Daten müssen für bestimmte Zeiträume aufbewahrt werden oder vollständig gelöscht werden. Das ER-Design sollte Metadatenfelder für Aufbewahrungsrichtlinien und Prüfprotokolle enthalten.
Versionsverwaltung und Schema-Evolution 🔄
In cloud-nativen Umgebungen ist eine Ausfallzeit bei Schema-Änderungen selten. Migrationen müssen online durchgeführt werden. Das ERD sollte Strategien zur Versionsverwaltung unterstützen.
Rückwärtskompatibilität
Neue Schema-Versionen sollten mit der Anwendungslogik rückwärtskompatibel sein. Dies ermöglicht eine schrittweise Einführung von Änderungen.
Migrationsmuster
- Spalte hinzufügen: Neue Felder hinzufügen, ohne bestehende Daten zu ändern.
- Doppeltes Schreiben: Während der Übergangsphase in alte und neue Strukturen schreiben.
- Umschaltung: Lesen und Schreiben nach der Datenmigration umschalten.
- Spalte löschen: Unbenutzte Felder erst nach Bestätigung, dass keine Abhängigkeiten bestehen, entfernen.
Häufige Fehler, die vermieden werden sollten ⚠️
Sogar erfahrene DBAs können Schwierigkeiten haben, sich an cloud-native Designs anzupassen. Hier sind häufige Fehler.
- Über-Normalisierung: Zu viele Joins erhöhen die Latenz in verteilten Systemen.
- Ignorieren von kalten Daten:Das Nicht-Archivieren historischer Daten kann die Kosten erhöhen und aktive Abfragen verlangsamen.
- Hartkodierte Grenzen: Festlegen willkürlicher Zeilengrenzen in der Anwendung, die Datenbankbeschränkungen umgehen.
- Ignorieren der Latenz: Abfragen entwerfen, die lokale Datenzugriffe voraussetzen, obwohl die Daten tatsächlich entfernt sind.
- Einzelne Ausfallpunkte Gestaltung eines primären Datenbankknotens, dessen Verlust das gesamte System anhält.
Implementierungs-Checkliste ✅
Bevor Sie ein cloud-natives Datenbankschema bereitstellen, überprüfen Sie die folgende Checkliste.
| Aufgabe | Priorität | Status |
|---|---|---|
| Definieren Sie die Sharding-Strategie | Hoch | Nicht begonnen |
| Lesen/Schreiben-Muster identifizieren | Hoch | Nicht begonnen |
| Planung für eventual consistency | Mittel | Nicht begonnen |
| Entwurf von Backup- und Wiederherstellungslösungen | Hoch | Nicht begonnen |
| Überwachungs-Alarme einrichten | Mittel | Nicht begonnen |
| Sicherheitsrichtlinien überprüfen | Hoch | Nicht begonnen |
Wartung und Überwachung 🔍
Eine cloud-native Datenbank erfordert kontinuierliche Überwachung. Das ERD ist kein statisches Dokument; es entwickelt sich mit der Anwendung weiter.
Wichtige Metriken
- Abfrage-Latenz: Verfolgen Sie durchschnittliche und p99-Antwortzeiten.
- Auslastung des Verbindungspools: Stellen Sie sicher, dass die Anwendung Spitzenlasten bewältigen kann.
- Speicherwachstum: Prognostizieren Sie zukünftige Kapazitätsanforderungen.
- Fehlerquoten: Überwachen Sie Transaktionsfehler und Rückgängigmachungen.
Automatisierung
Verwenden Sie automatisierte Tools, um Schemaabweichungen zu erkennen und Standards durchzusetzen. Manuelle Änderungen an Produktions-Schemata sollten minimiert werden, um menschliche Fehler zu reduzieren.
Zusammenfassung 🏁
Das Entwerfen von ER-Diagrammen für cloud-native Architekturen ist eine komplexe Aufgabe, die technische Einschränkungen mit geschäftlichen Zielen abwägt. Durch Fokus auf Skalierbarkeit, Konsistenzmodelle und Sicherheit können DBAs Systeme aufbauen, die Wachstum und Veränderung standhalten. Der Schlüssel besteht darin, Datenmodellierung als kontinuierlichen Prozess zu betrachten, anstatt sie als einmalige Einrichtung. Regelmäßige Überprüfungen und Einhaltung bewährter Praktiken stellen sicher, dass die Datenbank eine zuverlässige Grundlage für die Anwendung bleibt. 🌐

