








Daten bilden die Grundlage jedes digitalen Systems, von einfachen Webanwendungen bis hin zu komplexen Enterprise-Resource-Planning-Plattformen. Ohne einen strukturierten Ansatz zur Organisation dieser Informationen werden Systeme brüchig, langsam und schwer zu pflegen. Genau hier wird das Entity-Relationship-Diagramm, allgemein als ERD bekannt, unverzichtbar. Es dient als grundlegende Karte für die Datenbankgestaltung und übersetzt abstrakte geschäftliche Anforderungen in eine konkrete technische Struktur.
Dieser Leitfaden untersucht die Mechanik des ER-Modellierens, die Regeln für die Datenintegrität sowie die Strategien, die erforderlich sind, um skalierbare Architekturen zu entwickeln. Durch das Verständnis der Grundprinzipien von Entitäten, Beziehungen und Normalisierung können Architekten sicherstellen, dass ihre Datenebenen im Laufe der Zeit robust und effizient bleiben.
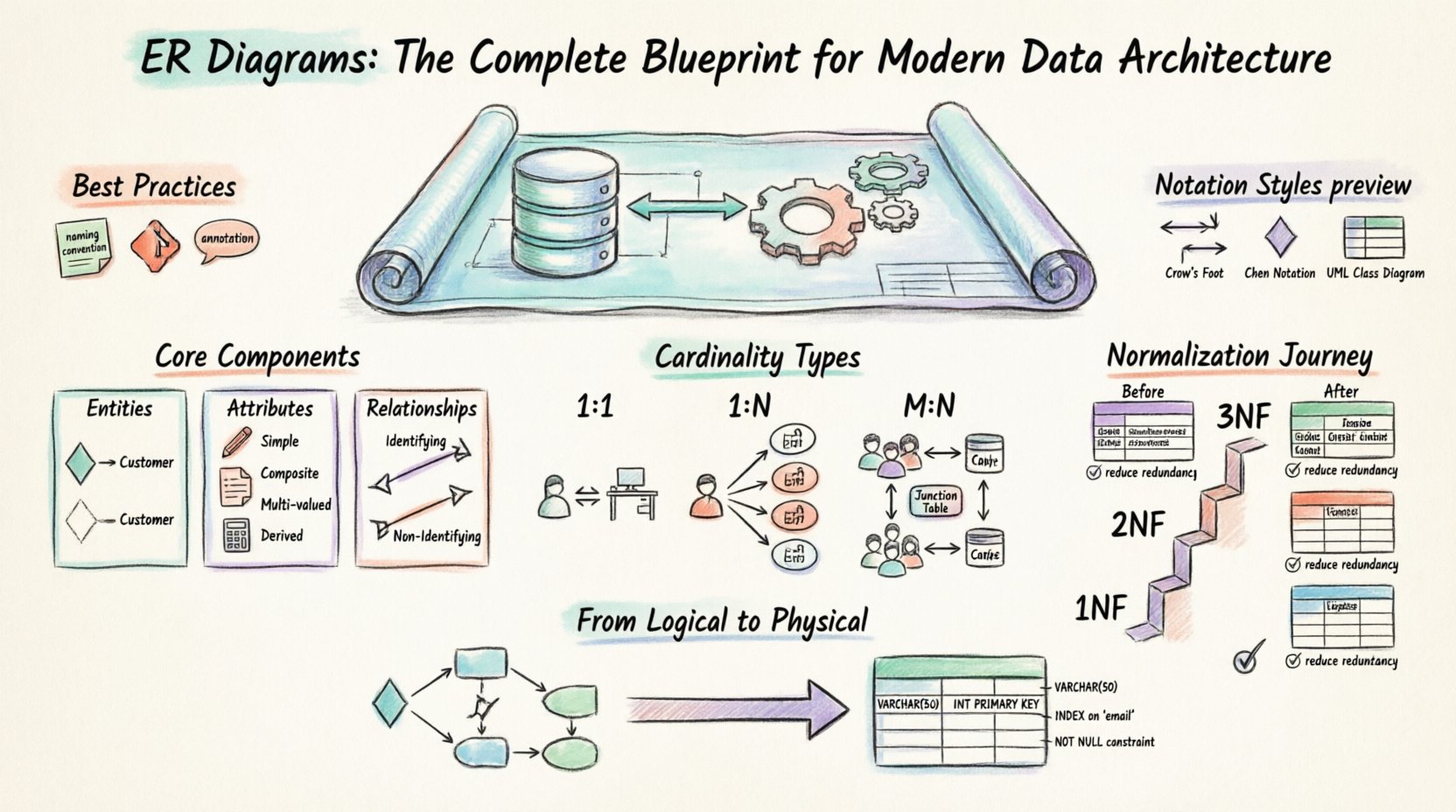
🔍 Was ist ein Entity-Relationship-Diagramm?
Ein Entity-Relationship-Diagramm ist eine visuelle Darstellung von Datenstrukturen und den Beziehungen zwischen ihnen. Es ist ein konzeptionelles Werkzeug, das während der Entwurfsphase der Datenbankentwicklung verwendet wird. Statt sich auf die physischen Speichermechanismen wie Festplattenblöcke oder Speicheradressen zu konzentrieren, fokussiert sich das ERD auf die logische Organisation der Daten.
Stellen Sie sich vor, es sei ein architektonischer Bauplan für ein Haus. Bevor Beton gegossen oder Ziegel gelegt werden, zeichnet ein Architekt eine Planung, die zeigt, wo Wände hingehen, wo Türen Räume verbinden und wie Versorgungsleitungen fließen. Ebenso zeigt ein ERD, wo Daten leben, wie sie miteinander verbunden sind und wie sie durch die Anwendung fließen.
Wichtige Zwecke der ER-Modellierung
- Kommunikation: Es schließt die Lücke zwischen technischen Teams und Geschäftssachverständigen. Visuelle Diagramme sind leichter verständlich als roher Code oder SQL-Skripte.
- Planung: Es erkennt potenzielle Probleme, bevor die Umsetzung beginnt. Designfehler sind auf Papier günstiger zu beheben als in der Produktion.
- Dokumentation: Es dient als Referenz für zukünftige Entwickler und erklärt, wie Daten strukturiert und miteinander verknüpft sind.
- Optimierung: Es hebt Redundanzen und Unzulänglichkeiten hervor, die zu langsameren Abfrageleistungen führen könnten.
🏗️ Kernkomponenten eines ERD
Um ein gültiges Diagramm zu erstellen, muss man die drei grundlegenden Bausteine verstehen. Jede Beziehung und jeder Einschränkung in einer Datenbank ergibt sich aus der Wechselwirkung dieser Elemente.
1. Entitäten
Eine Entität stellt ein eindeutiges Objekt oder Konzept innerhalb des Geschäftsbereichs dar. Im Kontext einer Datenbank entspricht eine Entität typischerweise einer Tabelle. Entitäten können sein:
- Starke Entitäten: Sie existieren unabhängig und verfügen über einen eigenen Primärschlüssel. Zum Beispiel eineKundeEntität existiert auch ohne eine zugehörigeBestellung.
- Schwache Entitäten: Sie hängen von einer starken Entität für ihre Existenz ab. EineBestellpositionkann nicht ohne eine übergeordneteBestellung.
Entitäten werden in der Standardnotation normalerweise durch Rechtecke dargestellt. Sie werden mit Singular-Nomen benannt, um die Klasse der Objekte darzustellen.
2. Attribute
Attribute beschreiben die Eigenschaften oder Merkmale einer Entität. Sie sind die Spalten innerhalb einer Tabelle. Attribute lassen sich in mehrere Kategorien einteilen:
- Einfache Attribute: Unteilbare Werte, wie ein Vorname oder Alter.
- Zusammengesetzte Attribute: Attribute, die in Unterteile zerlegt werden können, wie ein Adress (Straße, Stadt, Postleitzahl).
- Mehrwertige Attribute: Attribute, die mehrere Werte enthalten können, wie Telefonnummern oder Fähigkeiten.
- Abgeleitete Attribute: Werte, die aus anderen Attributen berechnet werden, wie Alter abgeleitet aus Geburtsdatum.
Das wichtigste Attribut ist das Primärschlüssel. Dieser eindeutige Bezeichner unterscheidet einen Datensatz von einem anderen innerhalb einer Entität. Ohne einen Primärschlüssel kann die Datenintegrität nicht gewährleistet werden.
3. Beziehungen
Beziehungen definieren, wie Entitäten miteinander interagieren. Sie zeigen die Einschränkungen und Assoziationen zwischen Datenpunkten an. Beziehungen sind das verbindende Gewebe der Datenbank.
- Beziehungen identifizieren: Eine schwache Entität hängt von einer starken Entität ab. Die Beziehung bestimmt das Vorhandensein der schwachen Entität.
- Nicht-identifizierende Beziehungen: Entitäten sind unabhängig. Die Beziehung besteht, aber bestimmt nicht das Vorhandensein.
🔗 Verständnis von Kardinalität und Modalität
Die Kardinalität definiert die Anzahl der Instanzen einer Entität, die mit jeder Instanz einer anderen Entität assoziiert sein können oder müssen. Dies wird oft als die Struktur „Ein-zu-Eins“, „Ein-zu-Viele“ oder „Viele-zu-Viele“ bezeichnet.
Die Modalität bezieht sich darauf, ob die Beziehung obligatorisch oder optional ist. Muss eine Aufzeichnungmüsseneine zugehörige Aufzeichnung haben, oder darf sie ohne eine solche existieren?
Typen der Kardinalität
| Kardinalität | Notation | Beispiel-Szenario |
|---|---|---|
| Ein-zu-Eins (1:1) | Ein ─── Ein | Ein Mitarbeiter hat einen Büroarbeitsplatz |
| Ein-zu-Viele (1:N) | Ein ─── Viele | Ein Kunde stellt viele Bestellungen auf |
| Viele-zu-Viele (M:N) | Viele ─── Viele | Viele Studierende melden sich in vielen Kursen an |
Viele-zu-Viele-Beziehungen sind besonders wichtig zu beachten. In einer physischen Datenbank wird eine direkte Viele-zu-Viele-Verbindung nicht unterstützt. Sie muss durch Einführung einer assoziativen Entität (einer Verknüpfungstabelle) aufgelöst werden, die die Beziehung in zwei Ein-zu-Viele-Beziehungen aufteilt.
⚖️ Normalisierungsprinzipien
Die Normalisierung ist der Prozess der Organisation von Daten, um Redundanz zu reduzieren und die Datenintegrität zu verbessern. Dabei werden große Tabellen in kleinere, logisch verbundene Tabellen aufgeteilt, und Beziehungen zwischen ihnen werden definiert. Ziel ist es sicherzustellen, dass jeder Datenbestand an nur einer Stelle gespeichert wird.
Erste Normalform (1NF)
Der erste Schritt bei der Normalisierung besteht darin sicherzustellen, dass:
- Alle Spaltenwerte sind atomar (unteilbar).
- Es gibt keine sich wiederholenden Gruppen oder Arrays innerhalb einer einzelnen Spalte.
- Jede Spalte enthält pro Zeile nur einen Wert.
Zum Beispiel eine FähigkeitenSpalte, die „Java, SQL, Python“ enthält, verstößt gegen die 1NF. Dies sollte in separate Zeilen oder eine separate Tabelle aufgeteilt werden.
Zweite Normalform (2NF)
Eine Tabelle befindet sich in 2NF, wenn sie in 1NF ist und alle nichtschlüsselbasierten Attribute vollständig vom Primärschlüssel abhängen. Dadurch werden partielle Abhängigkeiten eliminiert. Wenn eine Tabelle einen zusammengesetzten Primärschlüssel hat, muss jeder nichtschlüsselbasierte Spaltenwert vom gesamten Schlüssel abhängen, nicht nur von einem Teil davon.
Dritte Normalform (3NF)
Eine Tabelle befindet sich in 3NF, wenn sie in 2NF ist und keine transitiven Abhängigkeiten vorliegen. Das bedeutet, dass nichtschlüsselbasierte Attribute nicht von anderen nichtschlüsselbasierten Attributen abhängen sollten. Zum Beispiel, wenn Stadt von PLZ, und PLZ von Kunden-ID, die Speicherung von Stadt in der KundeTabelle führt zu Redundanz. Es ist besser, eine separate PLZTabelle zu haben.
📐 Notationsstandards
Verschiedene Notationen existieren, um ERDs darzustellen. Während die zugrundeliegende Logik gleich bleibt, variieren die visuellen Symbole. Die Wahl eines Standards sorgt für Konsistenz in der Dokumentation.
- Crow’s Foot: Die am häufigsten verwendete Notation in der modernen Datenbankgestaltung. Sie verwendet Linien mit spezifischen Enden (wie ein Vogelfuß), um die Kardinalität anzugeben. Sie ist intuitiv und von Gestaltungstools weitgehend unterstützt.
- Chen: Eine ältere Notation, bei der Beziehungen als Rauten und Entitäten als Rechtecke dargestellt werden. Sie ist sehr explizit hinsichtlich der Art der Beziehung, kann aber bei komplexen Modellen unübersichtlich werden.
- UML: Unified Modeling Language. Häufig in der Softwareentwicklung verwendet, passt sie ER-Konzepte an, um sie in den umfassenderen UML-Framework für die Systemgestaltung einzufügen.
🔄 Von der logischen zur physischen Gestaltung
Die Reise von einem abstrakten Diagramm zu einer funktionsfähigen Datenbank erfordert den Übergang von logischen zu physischen Modellen.
Logisches Datenmodell
Dieses Modell konzentriert sich auf die Struktur der Daten, unabhängig vom spezifischen Datenbankmanagementsystem. Es definiert Entitäten, Attribute und Beziehungen mit allgemeinen Begriffen. Es ist technologieunabhängig. In dieser Phase wird die Frage beantwortet: „Welche Daten benötigen wir und wie hängen sie zusammen?“
Physisches Datenmodell
Dieses Modell übersetzt die logische Gestaltung in die Spezifikationen eines Datenbanksystems. Es definiert Datentypen (z. B. Integer, Varchar, Timestamp), Indizes, Einschränkungen und Partitionierungsstrategien. Es beantwortet die Frage: „Wie speichern wir dies effizient?“
Während dieses Übergangs werden spezifische Entscheidungen getroffen:
- Datentypen: Entscheidung zwischen
INTvsBIGINTbasierend auf dem erwarteten Volumen. - Indizes: Hinzufügen von Indizes zu Spalten, die häufig in Suchbedingungen verwendet werden, um die Abrufgeschwindigkeit zu erhöhen.
- Einschränkungen: Durchsetzung von
NOT NULLRegeln oderUNIQUEEinschränkungen auf Datenbankebene. - Namenskonventionen: Übernahme einer Standardform wie
snake_casefür Tabellen und Spalten, um die Lesbarkeit zu gewährleisten.
🛡️ Häufige Herausforderungen bei der Datenmodellierung
Selbst erfahrene Architekten stoßen bei der Erstellung von ER-Diagrammen auf Hindernisse. Die frühzeitige Erkennung dieser Herausforderungen kann kostspielige Nacharbeiten vermeiden.
1. Mehrdeutigkeit in Geschäftsregeln
Interessenten beschreiben Datenanforderungen oft vage. „Wir müssen Benutzer verfolgen“ könnte eine einfache Liste oder ein komplexes System mit Rollen, Berechtigungen und Audit-Protokollen bedeuten. Klare Kommunikation ist entscheidend, um diese Mehrdeutigkeiten zu klären, bevor Linien im Diagramm gezogen werden.
2. Übernormalisierung
Während die Normalisierung Redundanz verringert, kann eine übermäßige Normalisierung die Daten über zu viele Tabellen zerstückeln. Dies führt zu komplexen Joins, die die Abfrageleistung verlangsamen. Es muss ein Gleichgewicht zwischen Datenintegrität und Leseleistung gefunden werden.
3. Ignorieren des zukünftigen Wachstums
Entwürfe konzentrieren sich oft auf aktuelle Anforderungen. Dennoch müssen Datenmodelle zukünftigen Änderungen Rechnung tragen. Eine Tabelle, die für eine einzige Telefonnummer entworfen wurde, sollte mehrere Nummern oder internationale Formate vorab berücksichtigen.
4. Fehlende Beziehungen
Es ist üblich, Entitäten zu definieren, aber die Verknüpfung zu vergessen. Eine ProduktTabelle ohne Verbindung zu einer KategorieTabelle macht die Kategorisierung unmöglich. Jede Entität sollte überprüft werden, um sicherzustellen, dass sie logisch mit dem Rest des Schemas verbunden ist.
📋 Best Practices für die Dokumentation
Ein Diagramm ist nur dann nützlich, wenn es verstanden wird. Die Dokumentation ergänzt das visuelle Modell.
- Konsistente Benennung:Verwenden Sie klare, beschreibende Namen. Vermeiden Sie Abkürzungen, es sei denn, sie sind Branchenstandards.
- Versionskontrolle:Behandeln Sie das Schema wie Code. Verfolgen Sie Änderungen am ERD im Laufe der Zeit, um die Entwicklung des Systems zu verstehen.
- Anmerkungen:Fügen Sie Notizen zum Diagramm hinzu, um komplexes Geschäftslogik oder Ausnahmen zu erklären, die visuell nicht dargestellt werden können.
- Überprüfungszyklen:Überprüfen Sie das Modell regelmäßig gemeinsam mit technischen und nicht-technischen Teammitgliedern, um eine Abstimmung sicherzustellen.
🚀 Die Rolle des ERD in modernen Systemen
In der Landschaft der modernen Datenarchitektur bleiben die Prinzipien der ER-Modellierung relevant, trotz des Aufkommens von NoSQL- und Graphdatenbanken. Während sich die Speichermechanismen ändern, bleibt der Bedarf, Beziehungen und Datenintegrität zu verstehen, bestehen.
Für SQL-basierte Systeme ist der ERD das primäre Gestaltungselement. Für NoSQL-Systeme beeinflusst er die Dokumentstruktur und Einbettungsstrategien. Für Graphdatenbanken definiert er die Knoten und Kanten explizit.
Die Datenmodellierung ist keine einmalige Aufgabe. Sobald sich die Geschäftsanforderungen entwickeln, muss auch der ERD sich weiterentwickeln. Dieser iterative Prozess stellt sicher, dass die Datenebene eine strategische Ressource bleibt und keine technische Belastung darstellt.
✅ Zusammenfassung der wichtigsten Erkenntnisse
- Grundlage:ERDs sind die Baupläne für die Datenbankgestaltung und gewährleisten logische Konsistenz.
- Komponenten:Entitäten, Attribute und Beziehungen bilden das zentrale Dreieck jedes Modells.
- Kardinalität:Das Verständnis von 1:1-, 1:N- und M:N-Beziehungen ist entscheidend für eine genaue Datenaufbereitung.
- Normalisierung:Wenden Sie 1NF, 2NF und 3NF an, um Redundanz zu reduzieren und Integrität zu gewährleisten.
- Entwicklung:Gehen Sie von logischen zu physischen Modellen über, um die Implementierung vorzubereiten.
- Dokumentation:Stellen Sie klare Namenskonventionen und Versionskontrolle für die langfristige Wartung sicher.
Durch Einhaltung dieser Prinzipien erstellen Architekten Systeme, die nicht nur heute funktionsfähig sind, sondern auch für morgen anpassungsfähig sind. Das ER-Diagramm ist mehr als eine Zeichnung; es ist ein Vertrag zwischen der Geschäftslogik und der technischen Umsetzung.

