











盯着一个看起来像一团乱麻的数据库模式,是任何数据架构师或开发人员都熟悉的体验。你打开建模工具,看到的不是清晰、逻辑分明的数据地图,而是交叉的线条、模糊的标签,以及似乎违背逻辑的实体。这种视觉混乱不仅仅是审美问题;它其实是结构性债务的症状,最终会耗费你的时间、金钱和系统稳定性。📉
当实体关系图(ERD)看起来破损时,通常意味着其底层设计原则已被破坏。这不仅仅是简单地在方框之间画线;而是要定义你的数据关系的真实情况。一张破损的图会导致一个破损的数据库,从而引发查询缓慢、数据不一致和难以维护的问题。好消息是,这些问题并非无法解决。通过回归数据库理论中的基础且永恒的原则,你可以恢复混乱中的秩序。本指南将带你诊断症状、理解根本原因,并应用经过验证的策略来修复你的模式。🛡️
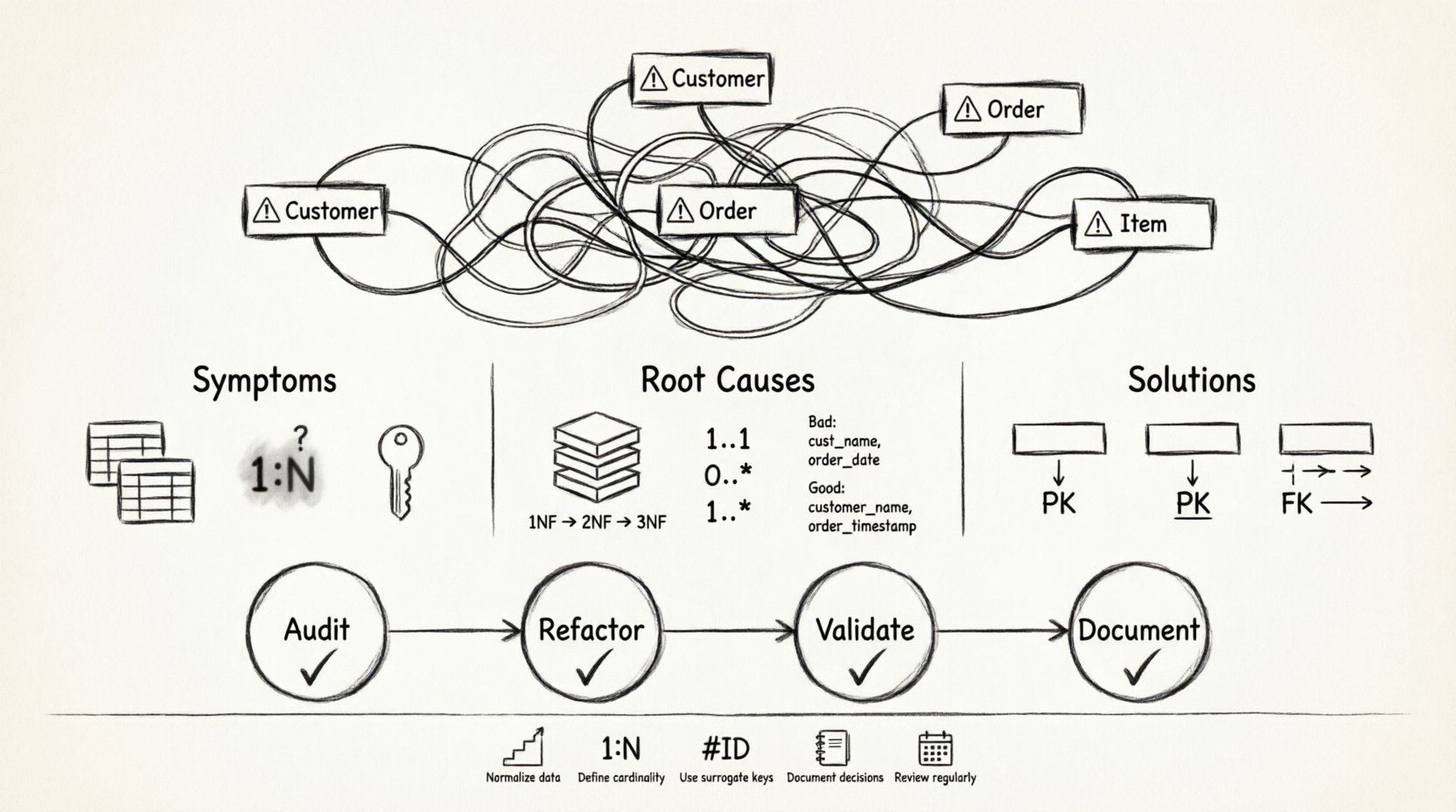
🔍 识别破损ERD的症状
在修复问题之前,你必须先识别其征兆。一个看起来‘破损’的数据库模型通常会表现出特定的视觉和逻辑警示信号。这些指标表明,你的业务需求与物理存储之间的抽象层存在问题。
- 意大利面式关系:线条相互无序交叉,导致无法追踪数据流向而不迷失方向。这通常发生在外键被随意放置而没有明确层级结构时。
- 冗余实体: 你看到两个或多个表存储着相同的信息,但名称略有不同。例如,同时拥有
客户和客户表,但它们的数据范围没有明确区分。 - 模糊的基数: 连接实体的线条未能清晰定义关系类型。是一对一?一对多?还是多对多?如果缺少或不一致使用乌鸦脚符号,意图就不明确。
- 循环依赖: 实体A与实体B相关,实体B与实体C相关,而实体C又回环到实体A。虽然有时是必要的,但通常表明数据未被正确规范化。
- 缺失主键: 主键缺失,或外键未链接到已定义的父表。这破坏了系统的参照完整性。
- 非原子值: 单个列包含多个信息片段,例如将“名字”和“姓氏”合并在一个字段中,或将标签列表以逗号分隔的字符串形式存储。
当你看到这些迹象时,图表正在表明数据模型尚未准备好投入实施。继续使用这样的图表会带来技术债务。接下来的部分将详细介绍如何利用既定的理论框架来解决这些问题。
🧠 根本原因:为什么模型会失败
理解为什么ERD看起来破损,需要审视设计过程。大多数失败源于优先考虑速度而非结构。当开发人员急于构建功能时,他们常常创建出仅满足即时查询需求的表,却忽视了更广泛的数据完整性要求。
1. 忽视规范化
规范化是组织数据以减少冗余并提高数据完整性的过程。跳过这一步是导致模式破损的最常见原因。如果没有规范化,你可能会面临数据异常,即在一个地方更新信息并不会在所有地方同步更新。
- 第一范式(1NF): 确保每一列都包含原子值。如果某一列包含列表,则该表不符合1NF。
- 第二范式(2NF): 要求表处于1NF,并确保所有非键属性完全依赖于主键。这可以防止部分依赖。
- 第三范式(3NF):要求表处于2NF,并确保不存在传递依赖。换句话说,非主键属性不应依赖于其他非主键属性。
如果您的图表显示某些列依赖于其他列而非仅依赖于主键,则存在规范化问题。这通常会导致表过于宽泛,难以高效查询。
2. 对基数的理解错误
基数定义了实体实例之间的数值关系。误解这一点会导致连接效率低下和查询复杂化。一个常见错误是将多对多关系建模为两个表之间的直接连接。实际上,在标准关系结构中,没有中间表就无法存在直接连接。
- 一对一:用于安全或特殊数据。在高流量系统中很少使用。
- 一对多:最常见的关系。一个父项可以有多个子项。
- 多对多:需要一个连接表。未能创建此桥梁会导致数据完整性问题。
3. 命名规范不佳
一张难以阅读的图表就是一张会被误用的图表。命名不一致,例如混用snake_case和camelCase,或使用像Table1和Table2这样的命名会增加认知负担。当开发人员无法立即理解一个表代表什么时,他们就会做出假设,从而导致错误。
🛠️ 恢复的永恒原则
要修复一个损坏的图表,你不需要新的工具或时髦的方法论。你需要应用关系理论的核心原则。这些原则经受住了时间的考验,因为它们触及了数据的根本性质。
1. 原子性与粒度
原子性原则规定,表中的每个单元格应只包含一个值。如果你有一个“地址”列,理想情况下应将其拆分为“街道”、“城市”、“州”和“邮政编码”。这样你就可以在不解析字符串的情况下查询地址的特定部分。这种粒度使你的数据在未来报告需求中更具灵活性。
2. 唯一标识
每个实体都必须有一个唯一标识符。这就是你的主键。没有它,你就无法可靠地引用特定行。如果您的图表中没有明确的主键,或者你依赖可能发生变化的自然键(如电子邮件地址),你就有数据漂移的风险。应使用代理键(如自增整数或UUID)来保证内部稳定性。
3. 参照完整性
这一原则确保表之间的链接保持有效。如果你删除一个客户,他们的订单会怎样?图表应反映删除和更新的规则。这通常通过外键来管理。一个损坏的图表通常包含指向无效位置的外键,或在不应允许的情况下允许空值。
4. 关注点分离
将不同的概念保留在独立的表中。除非有充分理由,否则不要将用户资料数据与认证凭据混合在同一张表中。这种分离使你能够独立地扩展和保护数据的不同部分。
📊 常见陷阱与标准解决方案
下表总结了在设计不良的ERD中发现的常见错误以及基于数据库理论的标准纠正措施。
| 陷阱 | 视觉症状 | 根本原因 | 标准解决方案 |
|---|---|---|---|
| 冗余数据 | 多个表中包含相同信息 | 违反第三范式 | 规范化表;删除重复列 |
| 缺失的关系 | 孤立的框 | 假设的逻辑 | 明确定义外键 |
| 多对多直接连接 | 连接两个多方实体的连线 | 关系约束 | 引入连接表 |
| 复合键 | 多个列作为主键 | 复杂性风险 | 尽可能使用代理键 |
| 空值过多的列 | 一列中有很多空单元格 | 可选数据管理不当 | 为可选属性创建独立的表 |
| 混乱的逻辑 | 到处都是交叉的连线 | 跳过了重构 | 按领域分组实体;逻辑性地重新绘制 |
🔄 修复过程:一个逐步框架
修复一个损坏的图表是一个系统性过程。它需要耐心和重构的意愿。不要急于应用修复措施;首先理解当前状态。
步骤 1:审计
首先记录现有的内容。不要假设你了解每个表的功能。创建一个数据字典,描述每一列的目的和预期的数据类型。这迫使你面对模式的真实情况。寻找存储列表的列、以字符串形式存储的日期,或与文本混合的ID。
- 列出所有实体及其属性。
- 识别所有现有的关系及其类型。
- 突出显示任何看起来冗余或模糊的数据。
步骤2:重构
完成审计后,应用规范化规则。将宽表拆分为更窄的表。将重复的组移动到独立的表中。确保每个表都有主键。如果发现多对多关系而没有桥接表,则创建一个。这一步是工作量最大的部分。
考虑业务规则。如果一个用户可以有多个地址,那么地址表必须独立于用户表存在。关系通过关联表或外键来管理,具体取决于特定的约束条件。
步骤3:验证
重构之后,验证新设计。检查是否存在循环依赖。确保删除记录不会导致其他记录孤立,除非这是有意的。验证所有外键都指向有效的主键。根据原始需求进行一次合理性检查,确保新结构仍然支持必要的查询。
步骤4:文档化
没有文档的图示迟早会再次失效。为你的实体添加注释。解释复杂关系背后的业务逻辑。这能确保未来的开发人员理解结构背后的“原因”,而不仅仅是“是什么”。
🛡️ 维护长期完整性
即使设计得再完美的图示,随着时间推移也可能退化。随着需求变化、新功能增加以及捷径被采用,为了保持模式的健康,你需要一套维护策略。
- 定期审查: 安排定期审查你的模式。寻找熵增的迹象。新表是否遵循相同的命名规范?关系是否一致?
- 版本控制: 将你的ERD视为代码。将其存储在版本控制系统中。这样可以追踪随时间的变化,并在更改引入错误时回滚。
- 约束强制: 使用数据库约束来强制执行你在图中定义的规则。不要仅依赖应用逻辑来防止无效数据。如果图中表明某个字段是必填的,数据库就应该强制执行这一点。
- 社区标准: 为你的组织采用统一标准。无论是命名规范、键类型还是关系表示法,一致性都能减少摩擦。
📝 最佳实践总结
构建一个健壮的数据库模式需要纪律。这意味着要抵制为了快速见效而牺牲长期稳定性的冲动。遵循这些原则,可以确保你的数据模型保持灵活且可靠。
- 始终对数据进行规范化,以减少冗余。
- 为每个关系定义明确的基数。
- 使用代理键以保证稳定性。
- 记录你的决策和业务规则。
- 定期审查你的模式,以防止退化。
一个损坏的ER图并非失败;而是一次优化你对数据理解的机会。通过应用这些永恒的原则,你将混乱的杂乱无章转变为一个有结构的资产,支持你应用程序的成长。今天投入清理图示的努力,将为你明天节省无数小时的调试时间。🚀
请记住,目标不仅仅是画出框框之间的连线。目标是创建一张准确反映你业务数据现实的地图。当你的图示符合完整性、规范化和清晰性的原则时,你的数据库就成为你可以自信地在此基础上构建的坚实基础。

