











जटिल सॉफ्टवेयर प्रणालियों की संरचना में, डेटाबेस स्कीमा सभी एप्लिकेशन तर्क के आधार के रूप में कार्य करता है। बड़े पैमाने पर बैकएंड विकास टीमों के लिए, जहां दसों इंजीनियर माइक्रोसर्विसेज या मोनोलिथिक संरचनाओं पर एक साथ काम कर रहे हों, डेटा असंगतता और संरचनात्मक विचलन का जोखिम महत्वपूर्ण है। एक साधारण एंटिटी-रिलेशनशिप आरेख (ईआरडी) केवल एक ड्राइंग अभ्यास नहीं है; यह डेटा प्रवाह के बारे में इंजीनियरिंग, उत्पाद और संचालन टीमों के बीच साझा समझ को एकरूप बनाने वाला एक महत्वपूर्ण संचार उपकरण है।
जब टीमें बड़े पैमाने पर काम करती हैं, तो डेटा संबंधों के बारे में गलत संचार की लागत उत्पादन घटनाओं, डेटा हानि या प्रदर्शन की अवरोधक स्थिति के कारण हो सकती है। एंटिटी के कैसे जुड़ती हैं, एक दूसरे से संबंधित हैं और एक दूसरे को सीमित करती हैं, इसका दृश्य प्रतिनिधित्व व्यक्तिगत डेवलपर के विशेषज्ञता से परे एक नक्शा प्रदान करता है। यह प्रणाली के भीतर जानकारी की संरचना के बारे में एकमात्र सत्य स्रोत के रूप में बनाता है।
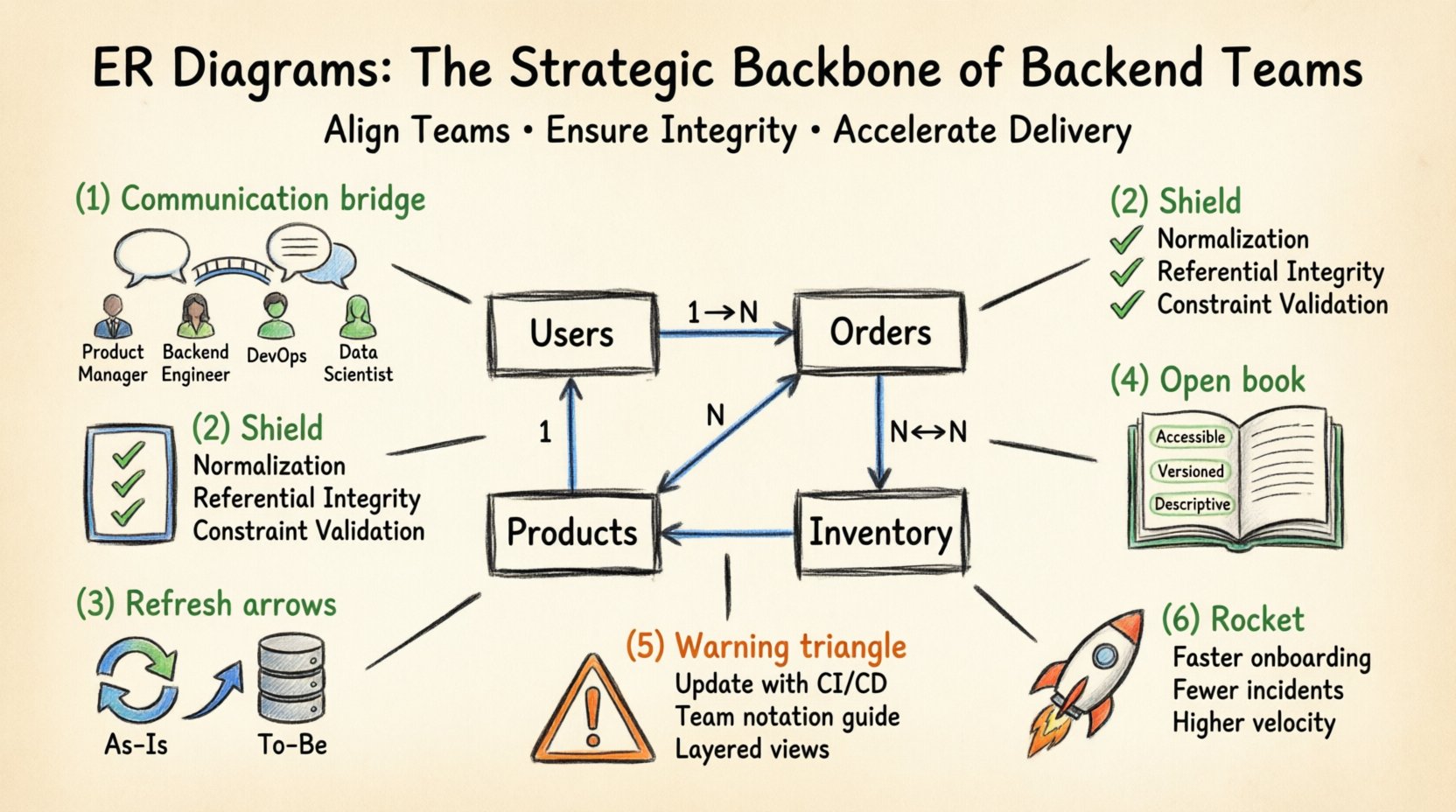
एंटिटी-रिलेशनशिप आरेख को परिभाषित करना 📐
ईआरडी एक डेटाबेस की तार्किक संरचना का दृश्य प्रतिनिधित्व है। यह एंटिटी को नक्शा बनाता है, जो आमतौर पर टेबल होती हैं, और उनके बीच संबंधों को। इन आरेखों में कार्डिनैलिटी को दर्शाने के लिए मानकीकृत नोटेशन का उपयोग किया जाता है, जैसे एक-एक, एक-बहुत, और बहुत-बहुत संबंध। जबकि तकनीकी कार्यान्वयन संबंधित और गैर-संबंधित प्रणालियों के बीच भिन्न हो सकता है, रणनीतिक उद्देश्य एक ही रहता है: स्पष्टता।
बैकएंड टीम के लिए, ईआरडी एक अनुबंध के रूप में कार्य करता है। डेटा डालने या प्रश्न करने के लिए कोई भी कोड लिखे जाने से पहले, आरेख सीमाओं को परिभाषित करता है। यह निर्दिष्ट करता है कि कौन से फील्ड अनिवार्य हैं, कौन से वैकल्पिक हैं, और विदेशी कुंजियाँ अलग-अलग टेबल को एक साथ कैसे बांधती हैं। यह परिभाषा तर्क त्रुटियों को रोकने के लिए महत्वपूर्ण है, जहां एक एप्लिकेशन किसी विशिष्ट डेटा संरचना की अपेक्षा करती है जो वास्तव में मौजूद नहीं है।
वितरित टीमों के बीच संचार 🤝
बड़े पैमाने पर विकास में अक्सर कई स्क्वाड शामिल होते हैं, जिनमें से प्रत्येक एक विशिष्ट क्षेत्र के मालिक होते हैं। एक एकीकृत दृश्य मानक के बिना, उत्पाद मालिक एक उपयोगकर्ता के कई पते होने की कल्पना कर सकता है, जबकि बैकएंड इंजीनियर एक समतल सूची के रूप में कार्यान्वयन कर सकता है, और डेटा विश्लेषक अलग पते की टेबल की अपेक्षा कर सकता है। इस असंगति के कारण एकीकरण के दौरान तनाव उत्पन्न होता है।
ईआरडी इन अंतरालों को पार करने में मदद करता है, क्योंकि यह विभिन्न क्षेत्रों में समझने योग्य एक भाषा प्रदान करता है।
- उत्पाद प्रबंधक:यह जांच सकते हैं कि डेटा मॉडल आवश्यक व्यावसायिक नियमों और उपयोगकर्ता प्रवाह का समर्थन करता है, बिना कोड सिंटैक्स को समझे।
- बैकएंड इंजीनियर:आरेख का उपयोग एपीआई एंडपॉइंट योजना बनाने, कुशल जॉइन्स सुनिश्चित करने और डेटा पहुंच पैटर्न के आधार पर कैशिंग रणनीतियों को डिज़ाइन करने के लिए करते हैं।
- डेवोप्स और एसआरईज़:डेटाबेस क्षमता, प्रतिलिपि रणनीतियों और बैकअप प्रक्रियाओं की योजना बनाने के लिए स्कीमा की समीक्षा करते हैं।
- डेटा वैज्ञानिक:यह निर्धारित करने के लिए संरचना का विश्लेषण करते हैं कि क्या डेटा विश्लेषण पाइपलाइन या मशीन लर्निंग मॉडल के लिए तैयार है।
दृश्य रूप में डेटा मॉडल को केंद्रीकृत करके, टीमें प्रणाली को समझने के लिए आवश्यक मानसिक भार को कम करती हैं। माइग्रेशन स्क्रिप्ट या स्कीमा परिभाषाओं के सैकड़ों पंक्तियों को पढ़ने के बजाय, एक टीम सदस्य आरेख को देखकर ग्राहकों, आदेशों और स्टॉक के बीच संबंधों को तुरंत समझ सकता है।
बड़े पैमाने पर डेटा अखंडता सुनिश्चित करना 🛡️
डेटा अखंडता डेटा के जीवनचक्र के दौरान उसकी सटीकता और सुसंगतता है। बड़ी टीम में, कई डेवलपर एक साथ स्कीमा को संशोधित कर सकते हैं। दृश्य गाइड के बिना, टकराव डालना आसान है। उदाहरण के लिए, एक डेवलपर एक टेबल में विदेशी कुंजी जोड़ सकता है जबकि दूसरा उसी टेबल को स्तंभ हटाने के लिए रिफैक्टर कर रहा हो।
ईआरडी उत्पादन समस्याओं में बदलने से पहले नियमों को लागू करने में मदद करता है। निर्भरताओं को दृश्य रूप से देखकर, वास्तुकार भविष्य में संभावित चक्रीय संदर्भ या अनाथ रिकॉर्ड की पहचान कर सकते हैं जो डेटा को दूषित कर सकते हैं।
ईआरडी अखंडता की रक्षा करने वाले मुख्य क्षेत्र निम्नलिखित हैं:
- नॉर्मलाइजेशन:आरेख टीमों को तब पहचानने में मदद करता है जब डेटा अनावश्यक रूप से दोहराया जा रहा हो। सही नॉर्मलाइजेशन स्टोरेज लागत को कम करता है और अपडेट अनोमाली को रोकता है।
- संदर्भात्मक अखंडता:यह निर्धारित करता है कि हटाने के बाद कैसे अन्य रिकॉर्ड प्रभावित होते हैं। यदि एक उपयोगकर्ता को हटा दिया जाता है, तो क्या उनके आदेशों को संग्रहीत किया जाना चाहिए या हटा दिया जाना चाहिए? आरेख इस संबंध को स्पष्ट करता है।
- सीमा वैधता:यह अद्वितीय सीमाओं और प्राथमिक कुंजियों को उजागर करता है, जिससे यह सुनिश्चित होता है कि पहचानकर्ता पूरे डेटासेट में अद्वितीय बने रहें।
रिफैक्टरिंग और माइग्रेशन को सुगम बनाना 🔄
सॉफ्टवेयर कभी भी स्थिर नहीं होता है। जैसे-जैसे व्यावसायिक आवश्यकताएं विकसित होती हैं, डेटा मॉडल को उसी के साथ विकसित होना चाहिए। बड़े पैमाने पर टीमों को आमतौर पर पुराने डेटा को नए संरचनाओं में स्थानांतरित करने की चुनौती का सामना करना पड़ता है। इस प्रक्रिया में जोखिम भरा होता है। यदि माइग्रेशन विफल होती है, तो डेटा खो सकता है, या एप्लिकेशन अनुपयोगी हो सकती है।
एक अद्यतन ERD इन माइग्रेशन के लिए नक्शा है। यह टीमों को बदलावों को लागू करने से पहले उनका सिमुलेशन करने की अनुमति देता है। माइग्रेशन की योजना बनाते समय, इंजीनियर अपने “वर्तमान” डायग्राम और “भविष्य में” डायग्राम की तुलना करके आवश्यक बदलावों की पूरी सूची बना सकते हैं।
इस दृश्यात्मक तुलना में मदद मिलती है:
- निर्भरताओं की पहचान करना: तोड़ने वाले बदलाव करने से पहले यह तय करना कि कौन सी सेवाएं विशिष्ट तालिकाओं पर निर्भर हैं।
- बंद होने के समय का अनुमान लगाना: स्कीमा बदलाव में शामिल डेटा के आयतन को समझना रखरखाव के खंड की योजना बनाने में मदद करता है।
- वापसी की योजना बनाना: यदि माइग्रेशन विफल होती है, तो डायग्राम इंजीनियरों को स्कीमा को पिछली स्थिति में सुरक्षित रूप से वापस लाने के तरीके को समझने में मदद करता है।
दस्तावेज़न एक जीवंत संपत्ति के रूप में 📚
दस्तावेज़न को लिखे जाने के तुरंत बाद अद्यतन न होने की समस्या आमतौर पर होती है। हालांकि, कोडबेस के साथ समन्वय में रखे गए ERD एक जीवंत संपत्ति बन जाता है। यह डेटा परत के लिए मुख्य दस्तावेज़न के रूप में कार्य करता है, जो अक्सर एप्लिकेशन परत से अधिक महत्वपूर्ण होता है।
जब कोई नया इंजीनियर टीम में शामिल होता है, तो वह कई हफ्तों तक कोड को पढ़कर डेटा प्रवाह को समझने के लिए बिता सकता है। एक ERD इस ज्ञान को एक ही दृश्य में संक्षेपित करता है। यह सीधे प्रश्न का उत्तर देता है, “ग्राहक डेटा कहाँ संग्रहीत है?”
ज्ञान स्थानांतरण के प्रभावी होने के लिए, डायग्राम को होना चाहिए:
- उपलब्ध: सभी टीम सदस्यों के लिए उपलब्ध, किसी विशिष्ट डेवलपर के स्थानीय पर्यावरण में बंद नहीं।
- संस्करणित: संस्करण नियंत्रण प्रणाली से जुड़ा हुआ ताकि ऐतिहासिक स्कीमा बदलावों की समीक्षा की जा सके।
- वर्णनात्मक: डायग्राम पर टिप्पणियाँ शामिल करें जो मानक संबंधों द्वारा प्रतिनिधित्व नहीं किए जा सकने वाले जटिल व्यावसायिक तर्क को समझाएं।
आम त्रुटियाँ और उनसे बचने के तरीके ⚠️
सबसे अच्छी इच्छा के साथ भी, टीमें अक्सर ERD का गलत उपयोग करती हैं या उनके बारे में लापरवाही बरतती हैं। इन त्रुटियों को पहचानना उनके प्रभावी उपयोग की पहली कदम है।
1. शुरुआती चरण में अत्यधिक डिज़ाइन करना
वास्तविक उपयोग के पैटर्न को समझे बिना एक सही, पूरी तरह से सामान्यीकृत डायग्राम बनाने से लचीले नहीं बदलने वाले प्रणाली के बनने की संभावना होती है। आमतौर पर बेहतर होता है कि आसान मॉडल से शुरुआत करें और उपयोग के पैटर्न उभरने पर उसे बेहतर बनाएं।
2. निर्माण के बाद डायग्राम को नजरअंदाज करना
यदि डायग्राम को कोड के साथ अद्यतन नहीं किया जाता है, तो यह भ्रम का कारण बन जाता है। इंजीनियर वास्तविक डेटाबेस स्कीमा के बजाय डायग्राम पर भरोसा कर सकते हैं, जिससे दोनों के अलग होने पर त्रुटियाँ हो सकती हैं।
3. केवल तालिकाओं पर ध्यान केंद्रित करना
एक ERD केवल तालिकाओं को दिखाना चाहिए। इसमें संबंध, कार्डिनैलिटी और सीमाएं भी दिखानी चाहिए। इस संदर्भ के बिना, डायग्राम केवल तालिकाओं की सूची है।
| त्रुटि | प्रभाव | उपाय की रणनीति |
|---|---|---|
| अद्यतन नहीं डायग्राम | विकास के दौरान भ्रम और त्रुटियां | आरेख अपडेट को CI/CD पाइपलाइन में एकीकृत करें |
| मानकों की कमी | टीमों के बीच असंगत नोटेशन | एक टीम-व्यापी नोटेशन गाइड स्थापित करें |
| बहुत अधिक विवरण | दृश्य अव्यवस्था और पठनीयता में कमी | परतदार दृश्यों का उपयोग करें (उच्च स्तर बनाम विस्तृत) |
| स्थिर दस्तावेज़ीकरण | ज्ञान जल्दी से अप्रचलित हो जाता है | स्कीमा फ़ाइलों से उत्पादन को स्वचालित करें |
दृश्यों को कार्यप्रणाली में एकीकृत करना ⚙️
ERD के मूल्य को अधिकतम करने के लिए, उन्हें विकास टीम के दैनिक कार्यप्रणाली में एकीकृत किया जाना चाहिए। इसका मतलब है कि एक बार आरेख बनाने और उसे फाइल करने के बाहर जाना।
1. डिज़ाइन चरण
एक नई सुविधा के डिज़ाइन चरण के दौरान, पहले डेटा मॉडल को खाका बनाया जाना चाहिए। इससे यह सुनिश्चित होता है कि विकास शुरू होने से पहले विशेषता के डेटा पहलू से लायक है। इससे बचा जाता है कि एक विशेषता बनाई जाए, लेकिन डेटाबेस आवश्यक प्रश्नों को कुशलता से समर्थित न कर सके।
2. कोड समीक्षा
स्कीमा परिवर्तनों की कोड परिवर्तनों के साथ समीक्षा की जानी चाहिए। जब कोई पुल अनुरोध माइग्रेशन को शामिल करता है, तो समीक्षक को जांचनी चाहिए कि क्या आरेख नए संरचना को दर्शाने के लिए अपडेट किया गया है। इससे दस्तावेज़ीकरण को कोड के साथ समकालीन रखा जाता है।
3. घटना प्रतिक्रिया
डेटा-संबंधित घटनाओं के पोस्ट-मॉर्टम के दौरान, ERD एक महत्वपूर्ण अभिलेख है। यह टीम को समझने में मदद करता है कि डेटा प्रवाह ने समस्या में कैसे योगदान दिया। क्या एक अनुपस्थित सीमा खराब डेटा को अंदर आने देती थी? क्या कोई संबंध प्रदर्शन की अवरोधक बन गया?
टीम वेग पर दीर्घकालिक प्रभाव 🚀
सटीक ERD को बनाए रखने में समय निवेश करने से लंबे समय में लाभ मिलता है। डेटा मॉडलिंग को प्राथमिकता देने वाली टीमें डेटा अखंडता से संबंधित उत्पादन घटनाओं का कम अनुभव करती हैं। वे नए इंजीनियरों को तेजी से शामिल करती हैं क्योंकि सीखने का ढलान कम होता है।
जब डेटा मॉडल स्पष्ट होता है, तो इंजीनियर डेटाबेस समस्याओं के निराकरण में बजाय व्यावसायिक समस्याओं को हल करने पर ध्यान केंद्रित कर सकते हैं। इस ध्यान के स्थानांतरण से उच्च गुणवत्ता वाले सॉफ्टवेयर और अंतिम उपयोगकर्ता को मूल्य के तेजी से वितरण की ओर जाता है।
इसके अलावा, स्पष्ट डेटा मॉडल बाहरी साझेदारों के साथ बेहतर सहयोग को सुविधाजनक बनाता है। यदि संगठन को API के माध्यम से डेटा प्रदर्शित करने की आवश्यकता है, तो अच्छी तरह से दस्तावेज़ीकृत ERD को सुरक्षित और कुशल एंडपॉइंट डिज़ाइन करने में मदद करता है।
डेटा मॉडलिंग अभ्यासों पर निष्कर्ष 📝
ERD की रणनीतिक कीमत सरल दस्तावेज़ीकरण से बहुत आगे तक जाती है। यह बड़े पैमाने पर बैकएंड वातावरणों में शासन, संचार और जोखिम प्रबंधन का एक उपकरण है। सॉफ्टवेयर आर्किटेक्चर के प्रथम नागरिक के रूप में डेटा मॉडल के साथ व्यवहार करके, टीमें ऐसे प्रणालियां बना सकती हैं जो दृढ़, स्केलेबल और रखरखाव योग्य हों।
जबकि प्रक्रिया अनुशासन और निरंतर रखरखाव की मांग करती है, विकल्प एक अव्यवस्थित वातावरण है जहां डेटा एक दायित्व है बजाय संपत्ति के। आरेख आधुनिक सॉफ्टवेयर प्रणालियों की जटिलता को समझने के लिए आवश्यक स्पष्टता प्रदान करता है।

