When a software system begins to scale, the data layer often becomes the most critical bottleneck. While application code can be rewritten and front-end interfaces redesigned, the database schema represents the foundational truth of the application. A poorly constructed Entity-Relationship Diagram (ERD) is not merely a visual inconvenience; it is a structural weakness that compounds over time. This analysis examines the tangible and intangible costs associated with flawed database modeling and the complex reality of refactoring these structures later in the development lifecycle.
Many teams treat schema design as a preliminary task, something to be finalized before the real coding begins. However, as requirements shift and business logic evolves, the rigidity of a poorly planned ERD becomes apparent. The cost of ignoring these details is not just measured in hours spent writing SQL, but in lost velocity, increased risk of downtime, and a degradation of team trust in the infrastructure.
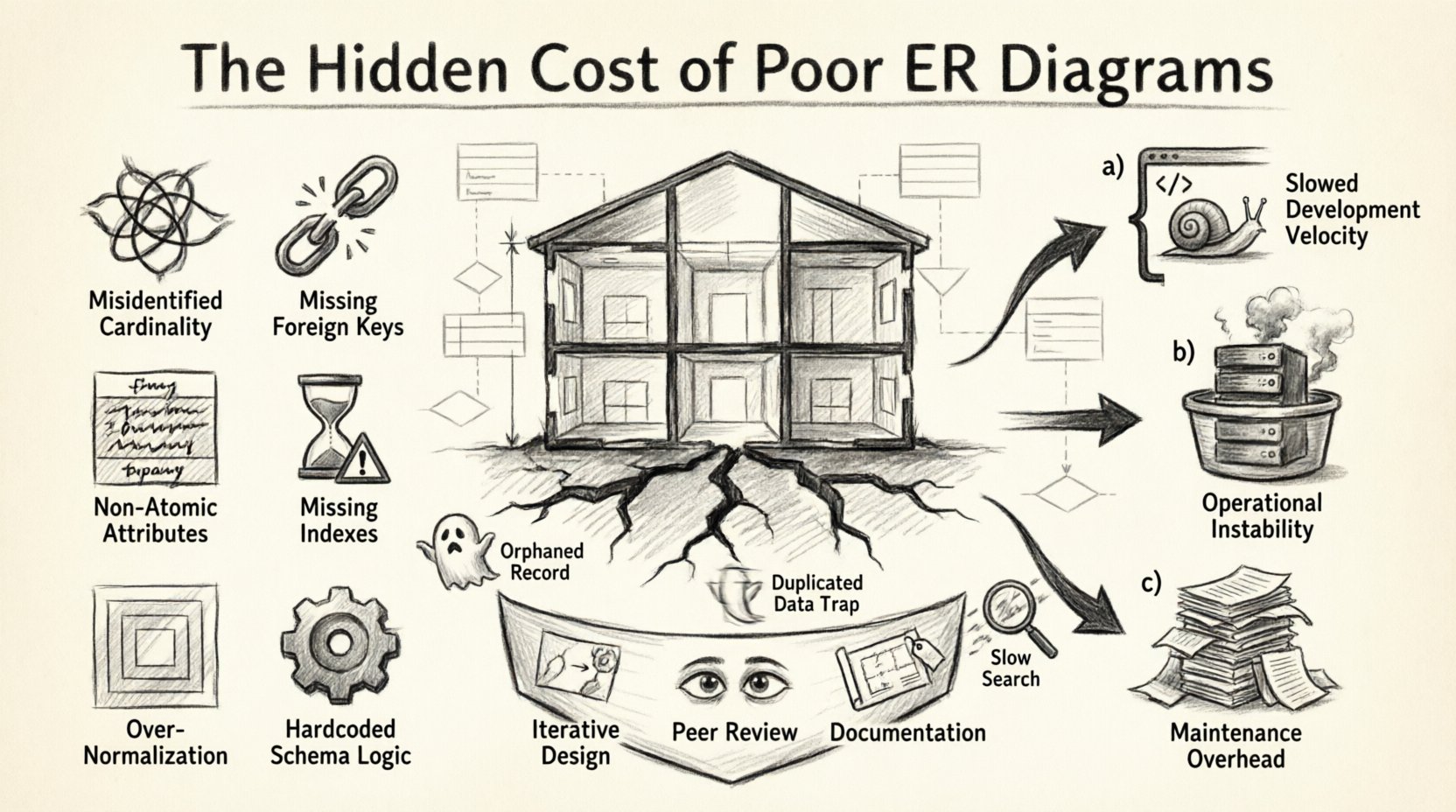
1. The Blueprint Analogy: Why the Schema Matters 🏗️
Think of a database schema as the architectural blueprint for a building. If the load-bearing walls are placed incorrectly, or if the plumbing pipes are routed inefficiently, the structure may stand initially. But over time, cracks appear. Piling on additional features onto a weak foundation leads to structural failure. In software, this manifests as slow queries, data inconsistencies, and an inability to add new features without breaking existing ones.
An ERD serves as the communication tool between stakeholders, developers, and data architects. It defines entities, their attributes, and the relationships between them. When this diagram is ambiguous or incomplete, it leads to:
- Implementation Ambiguity: Developers make assumptions about data integrity that may not match the business rules.
- Normalization Issues: Data is either overly fragmented, requiring excessive joins, or overly denormalized, leading to update anomalies.
- Constraint Gaps: Lack of foreign keys or check constraints allows invalid data to enter the system.
These issues accumulate. A small error in a relationship type might go unnoticed for months, only to cause a catastrophic failure when a specific report or migration is executed.
2. Anatomy of a Flawed Schema: Common Modeling Errors 🔍
Identifying the specific errors in an ERD is the first step in understanding the costs involved. Below is a breakdown of common modeling pitfalls that lead to significant technical debt.
| Category | Common Error | Impact on System |
|---|---|---|
| Relationships | Misidentified Cardinality (1:1 vs 1:N) | Inefficient storage, complex joins, data duplication. |
| Constraints | Missing Foreign Keys | Orphaned records, data integrity loss, manual cleanup required. |
| Attributes | Non-Atomic Columns | Difficulty querying, inability to index specific parts of data. |
| Performance | Missing Indexes on Foreign Keys | Slow joins, locking contention during writes, high CPU usage. |
| Design | Deeply Nested Normalization | Excessive table joins for simple reads, query complexity. |
| Scalability | Hardcoded Logic in Schema | Inflexible schema that cannot adapt to new business states. |
Each of these entries represents a point of friction. When a developer encounters an error in the schema, they often work around it with application-level logic. This pushes business rules into the codebase, creating a separation of concerns that is difficult to maintain.
3. Quantifying the Technical Debt 💰
The cost of poor design is rarely immediate. It is a slow drain on resources. We can categorize these costs into three main buckets: Development Velocity, Operational Stability, and Maintenance Overhead.
3.1 Development Velocity
When the schema is unclear, developers spend time reverse-engineering the data model instead of building features. They must:
- Trace data flow across multiple tables to understand a single field.
- Write complex SQL queries to compensate for missing relationships.
- Handle data cleaning tasks that should have been prevented at the source.
This slows down feature delivery. A sprint that should take three days to complete might stretch to five or six due to data debugging. This is a direct cost to the organization’s time and budget.
3.2 Operational Stability
Database issues often surface in production under load. Poor indexing strategies or lack of constraints can lead to:
- Lock Contention: When multiple transactions try to update the same poorly structured tables, the system grinds to a halt.
- Query Timeouts: Unoptimized joins cause the database to scan millions of rows unnecessarily.
- Data Corruption: Without proper constraints, invalid data can propagate through the system, making it hard to trust reports.
3.3 Maintenance Overhead
Every year a flawed schema exists, the cost to fix it increases. This is due to the accumulation of dependencies. New features are built on top of the old, flawed structure. Refactoring becomes like moving the foundation of a house while people are living inside it.
4. The Refactoring Process: Complexity and Risk 🛠️
Once the decision is made to refactor the database, the process is fraught with challenges. It is not simply a matter of altering tables. It involves a careful orchestration of migrations, data consistency checks, and minimal downtime.
4.1 The Migration Strategy
Refactoring requires migration scripts. These scripts must be idempotent and reversible. However, if the schema was poorly documented, writing these scripts becomes a guessing game. You must ensure that:
- Existing data is transformed correctly without loss.
- Running applications do not crash during the transition.
- Rollback plans are viable if something goes wrong.
In complex systems, this might require a dual-write strategy where new data is written to the new structure while old data is migrated in the background. This doubles the complexity of the application logic temporarily.
4.2 Downtime and Availability
Some structural changes, such as adding columns with defaults or re-indexing large tables, can lock the database. For high-availability systems, this is unacceptable. Refactoring often requires scheduling maintenance windows, which impacts user experience and revenue.
4.3 The Human Factor
Refactoring is also a psychological event for the team. If the team has to deal with a constant stream of data bugs caused by the schema, morale drops. They feel they are constantly fighting the infrastructure rather than building value. A clean, well-modeled database restores confidence in the platform.
5. Strategic Prevention: Building Resilient Models 🛡️
While refactoring is possible, prevention is far more cost-effective. Adopting a disciplined approach to ERD creation can mitigate most risks.
5.1 Iterative Design
Do not wait for the final requirements to design the schema. Start with the core entities and relationships that are stable. Allow the model to evolve. Treat the ERD as a living document that is updated alongside feature requests.
5.2 Peer Review of Data Models
Just as code is reviewed, database schemas should be reviewed. A fresh pair of eyes can spot:
- Redundant data fields.
- Missing relationships between tables.
- Potential naming conflicts.
- Violation of normalization rules.
This review process ensures that the model aligns with the business intent before a single line of migration code is written.
5.3 Documentation and Naming Conventions
Consistency is key. Establish strict naming conventions for tables and columns. Avoid abbreviations that are not widely understood. Document the business rule behind every foreign key. This ensures that anyone joining the team can understand the data without asking questions.
6. Post-Mortem Case Scenarios: Lessons Learned 📝
Let us examine hypothetical scenarios where poor ERD design led to significant issues, offering insights into what to avoid.
Scenario A: The Orphaned Record Crisis
The Situation: A team designed a system to track user orders and shipping addresses. They removed the foreign key constraint to improve write performance, assuming application logic would handle validation.
The Failure: Over time, users deleted their accounts but retained orders. The shipping addresses became orphaned. When the team tried to generate a tax report, the join failed because the user data was gone.
The Cost: The team had to write a script to manually link historical data to a generic “anonymous” user bucket. This took three days of engineering time and required a full database dump and restore to test safely.
Scenario B: The Denormalization Trap
The Situation: To speed up read performance, a team copied user profile data into the order table. They believed this would reduce join operations.
The Failure: When a user updated their name, the application updated the user table but failed to update the thousands of order records containing the old name. Reports showed inconsistent names for the same user.
The Cost: Data consistency was lost. The team had to decide whether to accept the inconsistency or implement a complex trigger system to sync data. They chose to refactor the schema to remove the duplication, requiring a rewrite of the application’s write logic.
Scenario C: The Indexing Blind Spot
The Situation: A search feature was built on a table with millions of rows. The developer assumed the primary key would be sufficient.
The Failure: As the table grew, queries on the search column slowed to a crawl. The database had to perform a full table scan.
The Cost: The system became unusable during peak hours. Adding an index later required a long-running operation that locked the table for hours, causing service disruption.
7. Future-Proofing Your Data Layer 🔮
The goal of any data modeling effort is to create a foundation that can withstand change. While no schema is perfect forever, a good ERD provides a clear path for evolution.
- Version Control: Treat your schema migrations as code. Store them in version control to track changes over time.
- Automated Testing: Include schema validation in your CI/CD pipeline. Ensure that migrations do not break existing queries.
- Monitoring: Monitor query performance to identify missing indexes or inefficient joins early.
- Community Standards: Follow established best practices for your specific database technology to ensure compatibility and performance.
Investing time in the ERD phase is not a delay; it is an acceleration. It reduces the friction of future development and ensures that the data remains a reliable asset rather than a liability.
Conclusion: The Cost of Ignorance vs. The Value of Planning ⚖️
The hidden cost of poor ER diagrams is often invisible until it is too late. It shows up as slower feature delivery, unstable production environments, and frustrated engineering teams. Refactoring a database is a high-stakes operation that requires precision, planning, and often, significant downtime.
By treating data modeling as a critical engineering task rather than an administrative chore, organizations can avoid the pitfalls of technical debt. A well-designed schema acts as a safeguard, ensuring that the application remains robust as it grows. The effort spent designing a solid ERD pays dividends in every line of code written afterward, every query executed, and every user served.
Do not wait for the post-mortem to realize the value of a good blueprint. Start planning with clarity, rigor, and a commitment to data integrity from day one.

