











Le modèle et la notation des processus métiers (BPMN) est la norme pour visualiser les flux de travail. Cependant, même les modélisateurs expérimentés créent souvent des diagrammes qui semblent corrects mais échouent lors de l’exécution. L’écart entre une représentation visuelle et un processus fonctionnel réside souvent dans des erreurs de conception subtiles. Lorsqu’un diagramme échoue, cela entraîne généralement des goulets d’étranglement dans le processus, des erreurs d’exécution ou des malentendus entre les parties prenantes. Ce guide explore les raisons techniques spécifiques pour lesquelles les diagrammes BPMN échouent et propose des stratégies de dépannage concrètes.
Comprendre les mécanismes fondamentaux de la spécification BPMN 2.0 est crucial. Un diagramme n’est pas simplement un dessin ; c’est un modèle formel. Si la syntaxe est correcte mais que la sémantique est fausse, le moteur ne peut pas interpréter l’intention. Nous analyserons les points de défaillance courants, allant de la logique des passerelles aux erreurs de flux de données.
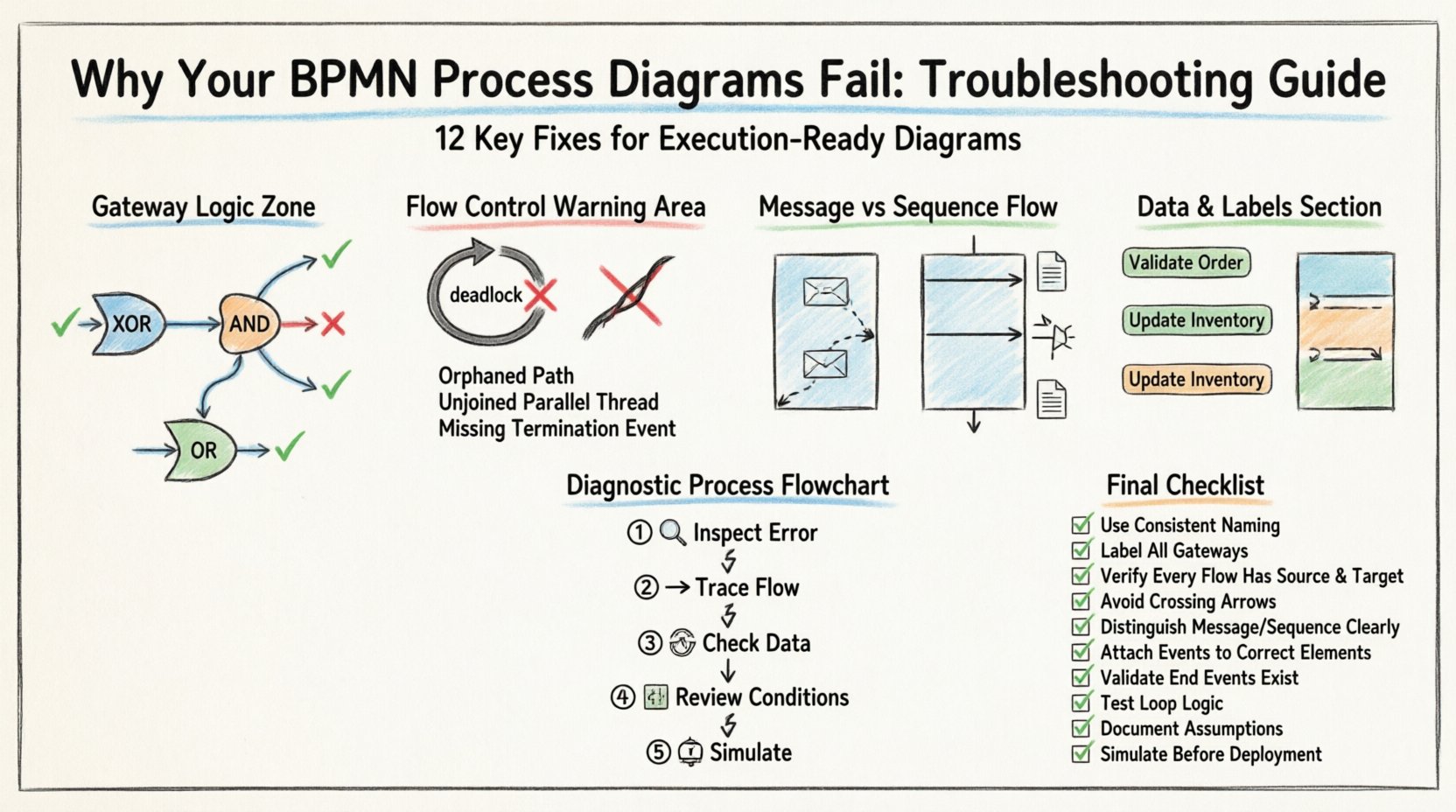
1. Erreurs sémantiques dans la logique des passerelles ⚙️
La cause la plus fréquente d’échec du processus est une configuration incorrecte des passerelles. Les passerelles contrôlent le flux du processus. Si la logique est ambiguë, le moteur d’exécution peut générer une erreur ou se comporter de manière imprévisible.
Passerelles exclusives vs. passerelles inclusives
Les modélisateurs confondent souvent les passerelles exclusives (XOR) avec les passerelles inclusives (OR). Bien qu’elles aient l’air similaires, leur comportement détermine la manière dont les chemins sont activés.
- Passerelle exclusive :Uniquement un chemin sortant est suivi. Les conditions sur les flux de séquence sortants doivent être mutuellement exclusives. Si deux conditions sont vraies, le processus échoue.
- Passerelle inclusive :Un ou plusieurs chemins sortants peuvent être suivis. Cela est utilisé lorsque plusieurs conditions pourraient être vraies simultanément.
Astuce de dépannage :Examinez chaque chemin sortant d’une passerelle. Assurez-vous que les conditions couvrent tous les résultats possibles. Si une condition manque, le processus peut rester bloqué en attendant une condition qui ne sera jamais évaluée comme vraie.
Passerelles parallèles (ET)
Les passerelles parallèles divisent le flux en threads concurrents. Une erreur courante survient lorsque les threads ne sont pas correctement regroupés.
- Si une passerelle parallèle se divise en deux chemins, ceux-ci doivent finalement se rencontrer à une passerelle de regroupement parallèle afin de se synchroniser.
- Laisser un thread ouvert sans point de regroupement crée un « thread fantôme » qui continue de s’exécuter indéfiniment en arrière-plan.
- Mélanger des flux exclusifs et parallèles sans synchronisation appropriée entraîne des conditions de course.
Liste de contrôle pour les passerelles :
- Toutes les conditions sortantes sont-elles évaluées ?
- Les threads parallèles ont-ils des points de regroupement correspondants ?
- Des chemins par défaut sont-ils définis pour les passerelles exclusives afin d’éviter les blocages ?
2. Contrôle du flux et blocages 🔗
Un processus bien structuré ne devrait jamais atteindre un état où aucune action ultérieure n’est possible, tout en restant incomplet. Cela est connu sous le nom de blocage.
Chemins orphelins
Un chemin orphelin survient lorsque un flux de séquence conduit à un point où aucune activité ultérieure n’est définie. Cela survient souvent lorsque :
- Supprimer une activité sans reconnecter les flux entrants et sortants.
- Créer un chemin qui se termine brusquement au milieu d’une voie ou d’un pool.
- Utiliser un événement intermédiaire de message sans flux de message correspondant.
États de fin implicites
Les processus doivent se terminer explicitement. Si un flux atteint une activité qui ne possède pas de flux de séquence sortant, l’instance du processus se termine. Bien que cela puisse parfois être intentionnel, cela est souvent une erreur. Chaque processus doit se terminer par un événement de fin pour signaler clairement sa complétion.
Tableau : Erreurs courantes de flux et leur impact
| Type d’erreur | Définition | Impact sur l’exécution |
|---|---|---|
| Bloquage | Le processus attend indéfiniment une condition | L’instance du processus se bloque ; une intervention manuelle est requise |
| Flux orphelin | Le flux de séquence conduit à aucune activité | L’instance du processus se termine de manière inattendue |
| Parallélisme non joint | Division parallèle sans jointure | Perte de ressources ; plusieurs instances des tâches suivantes |
| Absence de chemin par défaut | Passerelle exclusive sans chemin par défaut | Le processus se bloque si aucune condition n’est remplie |
3. Types d’événements et flux de messages 📨
Les événements marquent le début, le milieu et la fin des activités du processus. L’utilisation incorrecte des types d’événements est une source principale d’échec de conception.
Flux de message vs. flux de séquence
C’est la distinction la plus critique dans BPMN.
- Flux de séquence : Représente l’ordre des activités au sein d’un seul processus ou au sein d’une seule pool. Il implique un flux de contrôle strict.
- Flux de message : Représente la communication entre deux participants différents (pools) ou entre une tâche et un événement limite. Il implique un échange de données, et non un contrôle.
Erreur courante : Connecter deux tâches situées dans des pools différents par un flux de séquence. Cela provoquera une erreur de validation. Vous devez utiliser un flux de message et vous assurer que les deux tâches sont bien attachées aux bonnes limites.
Événements limites
Les événements limites vous permettent de définir des chemins alternatifs lorsqu’un événement imprévu se produit (par exemple, une erreur ou un délai d’attente dépassé). Ils doivent être attachés à l’activité qu’ils surveillent.
- Point d’attachement : Assurez-vous que l’événement est attaché à la bordure de l’activité, et non à l’intérieur.
- Interrompre vs. Non-interrompre : Les événements interrompant annulent l’activité. Les événements non interrompant permettent à l’activité de continuer pendant le traitement de l’événement. Choisir le mauvais type modifie entièrement la logique métier.
4. Objets de données et variables 📄
Les processus manipulent des données. Si le modèle de données n’est pas intégré au diagramme, le processus ne peut pas s’exécuter.
Entrée et sortie de données
Les tâches doivent définir explicitement les données qu’elles consomment et produisent. Toutefois, ajouter chaque variable au diagramme peut encombrer la vue. Utilisez des objets de données pour représenter un stockage temporaire de données ou des références.
- Données d’entrée : Assurez-vous que la tâche a accès aux variables requises avant le début de l’exécution.
- Données de sortie : Assurez-vous que les résultats sont stockés ou transmis à la tâche suivante via un flux de séquence.
Objets de données globaux
Pour les processus qui s’étendent sur plusieurs pools, utilisez des objets de données globaux. Cela garantit que le contexte des données est partagé correctement au-delà des frontières d’interaction.
Règle de validation : Toute tâche qui nécessite des données doit avoir un chemin clair pour recevoir ces données. Si une tâche attend une entrée qui n’arrive jamais, le processus s’arrête.
5. Clarté visuelle et conventions de nommage 👁️
Un diagramme difficile à lire est sujet à des malentendus. Bien que la clarté visuelle n’entraîne pas toujours des erreurs d’exécution, elle provoque des erreurs d’adoption. Les parties prenantes doivent comprendre le modèle pour y faire confiance.
Meilleures pratiques pour l’étiquetage
- Étiquettes des activités : Utilisez le format verbe-nom (par exemple, « Soumettre la demande », et non « Demande »).
- Étiquettes des passerelles : Indiquez clairement la condition (par exemple, « Valide ? », « Montant > 1000 »).
- Étiquettes des événements : Décrivez le déclencheur (par exemple, « Commande reçue », « Erreur : Délai dépassé »).
Rangs et pools
Les rangs organisent les tâches par rôle ou système. La confusion survient lorsque :
- Les tâches sont placées en dehors d’un pool ou d’un rang.
- Le même rôle apparaît dans plusieurs rangs sans raison claire.
- Les rangs sont trop étroits, ce qui fait que le texte est coupé.
Règle de base : Chaque filet doit représenter une responsabilité distincte. Si une tâche nécessite une entrée provenant d’un autre filet, assurez-vous que le flux de message traverse correctement la frontière.
6. Gouvernance et gestion des versions 📚
Même un diagramme parfait peut échouer s’il n’est pas correctement géré. Les modèles de processus évoluent. Sans gouvernance, les versions obsolètes entraînent la confusion.
Gestion des versions
Maintenez toujours l’historique des versions. Si une modification est apportée, la version précédente doit être archivée. Cela empêche le moteur d’exécution de lancer un modèle obsolète.
- Utilisez des numéros de version clairs (par exemple, v1.0, v1.1).
- Documentez la raison du changement dans les notes de version.
- Assurez-vous qu’une seule version la plus récente est active dans l’environnement d’exécution.
Normes de validation
Mettez en place un processus de validation avant la publication.
- Vérification syntaxique :Exécutez des vérifications automatisées pour garantir la conformité BPMN.
- Vérification sémantique :Revoyez la logique avec un expert du domaine.
- Vérification visuelle :Assurez-vous que le diagramme est propre et lisible.
7. Scénarios avancés de dépannage 🔍
Certaines problématiques sont subtiles et nécessitent une inspection approfondie.
Sous-processus d’événement
Les sous-processus d’événement vous permettent de définir un sous-processus déclenché par un événement plutôt que par un flux de séquence. Une erreur courante consiste à placer un événement de départ à l’intérieur d’un sous-processus déjà déclenché par un événement. Cela crée des déclencheurs imbriqués qui peuvent troubler le moteur.
- Assurez-vous que l’événement de départ du sous-processus est correctement configuré.
- Vérifiez si le sous-processus interrompt le flux principal.
Gestion des transactions
Pour les tâches nécessitant un comportement atomique (tout ou rien), utilisez les sous-processus de transaction. Si une tâche échoue, toute la transaction est annulée. Le fait de ne pas définir cette portée peut entraîner des mises à jour partielles des données.
8. Processus de diagnostic étape par étape 📝
Lorsqu’un processus échoue, suivez cette approche systématique pour identifier la cause racine.
- Examinez le message d’erreur : Le moteur fournit généralement un code d’erreur spécifique. Notez l’ID de la tâche ou l’ID de la passerelle.
- Suivez le flux : Suivez le flux de séquence en sens inverse à partir du point d’erreur jusqu’au début.
- Vérifier le contexte des données :Vérifiez si toutes les variables requises existent au moment de la défaillance.
- Examiner les conditions :Évaluer la logique booléenne sur toutes les passerelles menant à l’erreur.
- Simuler :Si possible, exécuter une simulation avec des données d’exemple pour reproduire la défaillance.
9. Pièges courants dans les processus complexes 🧩
À mesure que les processus deviennent plus complexes, le risque d’erreurs augmente de façon exponentielle.
Boucles imbriquées
Créer une boucle à l’intérieur d’une autre peut entraîner une exécution infinie. Assurez-vous que les conditions de sortie sont clairement définies pour chaque boucle.
Attribution de tâches concurrentes
Si plusieurs tâches sont attribuées simultanément à la même personne, une contention de ressources se produit. Utilisez des passerelles parallèles pour diviser les tâches, mais assurez-vous que la logique de fusion agrège correctement les résultats.
Dépendances avec des systèmes externes
Les processus dépendent souvent de systèmes externes. Si un appel externe expiré, le processus doit gérer l’erreur de manière appropriée. Ne comptez pas sur le système externe pour signaler la fin ; utilisez des délais d’attente ou des événements d’erreur.
10. Construction d’un modèle résilient 🛡️
Pour éviter les défaillances futures, adoptez une approche rigoureuse de modélisation.
- Commencez par le simple :Modélisez d’abord le parcours normal. Ajoutez le traitement des erreurs plus tard.
- Utilisez des modèles :Créez des modèles standards pour les schémas courants (par exemple, Approbation, Notification, Intégration).
- Revue par les pairs :Faites revue du diagramme par un autre modélisateur avant la publication.
- Documentation :Maintenez un document distinct expliquant la logique complexe qui ne peut pas tenir sur le diagramme.
11. Métriques et amélioration continue 📈
Une fois qu’un processus est en production, surveillez sa performance. Les métriques peuvent révéler des défauts de conception qui n’étaient pas apparents lors de la modélisation.
- Temps d’exécution :Si une tâche prend trop de temps, vérifiez les goulets d’étranglement ou les contraintes de ressources.
- Taux d’échec :Un taux élevé d’échecs à une tâche spécifique indique une erreur de logique ou un problème de qualité des données.
- Débit : Assurez-vous que le processus peut gérer les pics de charge sans erreurs de file d’attente.
Utilisez ces métriques pour affiner continuellement le modèle BPMN. Un modèle n’est jamais terminé ; c’est un artefact vivant qui doit s’adapter aux besoins commerciaux changeants.
12. Liste de contrôle finale pour les modélisateurs ✅
Avant de finaliser n’importe quel diagramme BPMN, passez en revue cette liste de contrôle complète.
- Tous les pools et les voies sont-ils définis ?
- Chaque tâche a-t-elle un propriétaire clair ?
- Tous les points de décision sont-ils correctement reliés ?
- Y a-t-il un chemin par défaut pour les points de décision exclusifs ?
- Les flux de messages traversent-ils les limites des pools ?
- Tous les événements de départ et d’arrivée sont-ils définis ?
- Le diagramme est-il dépourvu de lignes qui se croisent ?
- Les étiquettes sont-elles descriptives et cohérentes ?
- Le numéro de version est-il à jour ?
- Les objets de données ont-ils été validés ?
En appliquant rigoureusement ces étapes de dépannage et en suivant les bonnes pratiques, vous pouvez vous assurer que vos diagrammes de processus sont robustes, précis et prêts à être exécutés. L’objectif n’est pas seulement de dessiner une image, mais de définir un mécanisme fiable pour les opérations commerciales.

