Building a robust backend architecture requires more than just writing efficient code; it demands a foundational understanding of how data is structured, stored, and retrieved under pressure. At the heart of this infrastructure lies the Entity Relationship Diagram (ERD). While often treated as a static blueprint created during the initial planning phase, a well-designed ERD serves as the dynamic backbone of high-traffic systems. When traffic spikes, the database schema dictates performance, latency, and availability. A poorly structured model can lead to cascading failures, whereas a scalable design accommodates growth seamlessly.
This guide explores the technical nuances of constructing ER diagrams that withstand heavy loads. We will move beyond basic normalization and examine how relationships, constraints, and physical storage strategies interact in distributed environments. Whether you are designing for millions of concurrent users or simply planning for future expansion, the principles outlined here provide a framework for resilient data modeling.
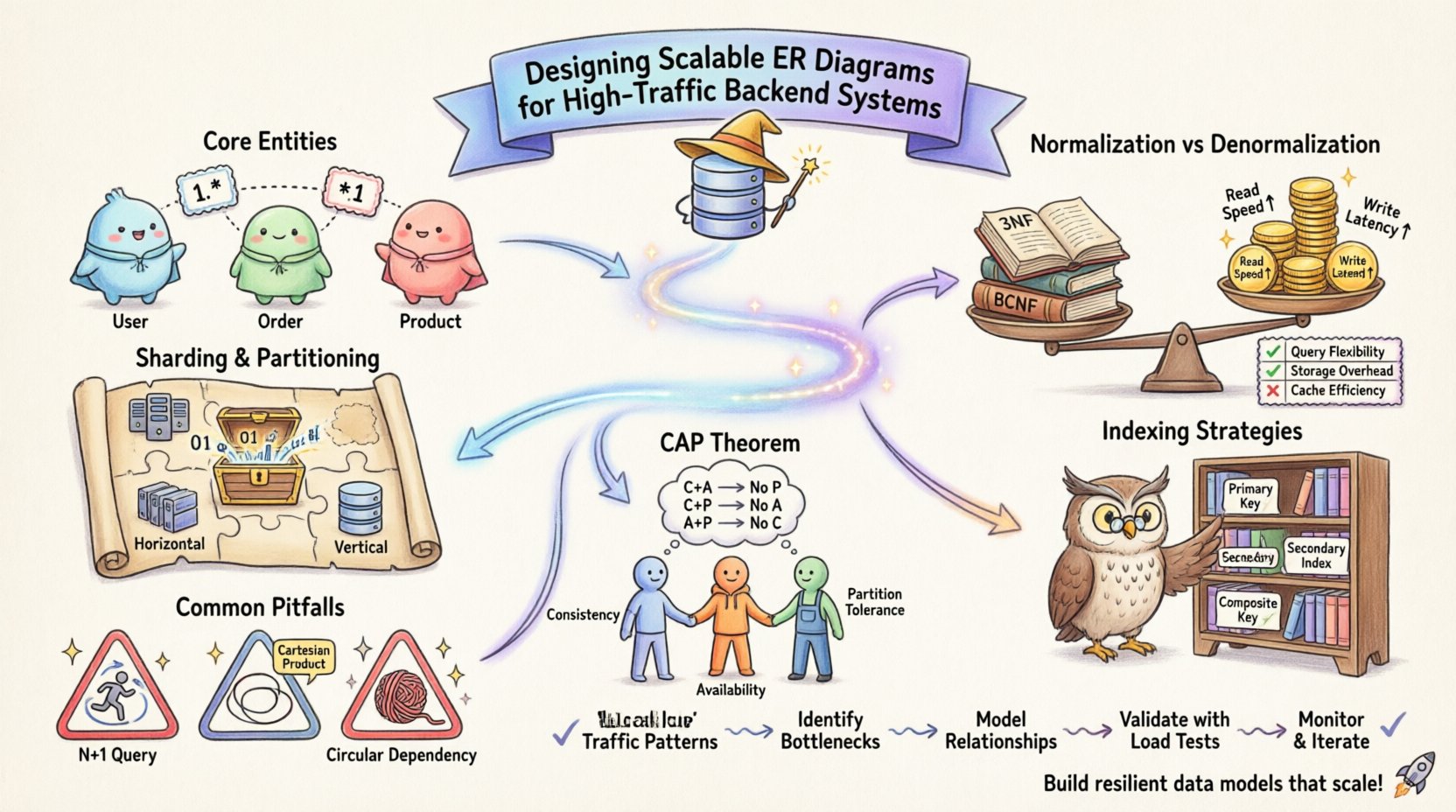
🏗️ Understanding Entity Relationship Modeling at Scale
The fundamental unit of an ER diagram is the entity, representing a distinct object or concept within your system. In a low-traffic environment, simplicity often reigns supreme. However, as transaction volumes increase, the complexity of interactions between entities grows exponentially. High-traffic systems require a shift in perspective from “how should this data look?” to “how will this data perform under load?”.
- Identify Core Entities: Determine which data objects are accessed most frequently. These are your hot paths.
- Analyze Cardinality: Define the relationships between entities. One-to-many, many-to-many, and one-to-one relationships each carry different performance implications.
- Attribute Granularity: Decide how much detail to store within an attribute. Overly granular attributes can bloat row sizes, while overly broad attributes can hinder query specificity.
When designing for scale, the physical layout of data becomes as important as the logical structure. The ERD must reflect not only business logic but also the operational constraints of the storage engine. For instance, some systems handle row-level locking differently than page-level locking. Your diagram should anticipate these constraints by minimizing contention points.
📊 Normalization vs. Denormalization: The Performance Trade-off
Normalization is the process of organizing data to reduce redundancy and improve integrity. While traditionally taught as a universal best practice, high-traffic systems often require a balanced approach. Strict adherence to the Third Normal Form (3NF) can introduce excessive join operations. In a distributed or high-concurrency environment, joins across multiple tables can become significant bottlenecks.
Conversely, denormalization involves duplicating data to reduce the need for joins. This strategy improves read performance but complicates write operations. You must maintain consistency across duplicated fields, which adds logic to your application layer.
| Strategy | Read Performance | Write Performance | Data Consistency | Storage Cost |
|---|---|---|---|---|
| Full Normalization | Lower (Multiple Joins) | Higher (Single Write) | High | Low |
| Partial Denormalization | High (Fewer Joins) | Moderate (Update Duplication) | Moderate | Moderate |
| Full Denormalization | Very High | Low (Complex Logic) | Low (Requires Sync) | High |
Choosing the right balance depends on your read-to-write ratio. If your system is read-heavy, such as a content feed or news platform, denormalization is often necessary. If your system is write-heavy, like a transaction ledger, normalization helps prevent anomalies.
🌐 Strategies for Read and Write Optimization
Optimizing for high traffic involves specific techniques that influence the shape of your ERD. These strategies focus on reducing the time it takes to fetch or store information.
1. Caching Strategies Reflected in Schema
When designing your data model, consider how data will be cached. Frequently accessed entities should be structured to allow for easy serialization. Avoid storing large, variable-length blobs in tables that are frequently joined. Instead, store a reference key and fetch the blob separately when needed. This reduces memory pressure on the primary cache layer.
2. Partitioning and Sharding Keys
As data grows, single-table storage becomes inefficient. Sharding splits data across multiple nodes. Your ERD must define a shard key clearly. This key determines how rows are distributed. If the shard key is chosen poorly, you may end up with “hot partitions” where one node handles significantly more traffic than others.
- Horizontal Sharding: Splits rows based on a key. The ERD must show how the key is distributed.
- Vertical Sharding: Splits columns across tables. Useful for separating heavy columns (like logs) from core transactional data.
🔗 Managing Relationships in Partitioned Data
Relationships are the glue that holds a database together, but in a distributed system, they can become a source of latency. Foreign keys enforce referential integrity, but in a sharded environment, enforcing these constraints across nodes is expensive.
Handling Many-to-Many Relationships
Many-to-many relationships require a junction table. In a high-traffic scenario, this table can become a bottleneck. If you query frequently, consider denormalizing the relationship. Instead of joining the junction table, store the relationship ID directly on the parent entity if the cardinality allows. This reduces the depth of the query.
Self-Referencing Entities
Some entities reference themselves, such as categories or hierarchical comments. Design these relationships carefully. Deep recursion in queries can exhaust system resources. Limit the depth of self-referencing chains in your logic, or flatten the structure where possible using materialized paths.
🔍 Indexing Strategies for Performance
An ERD defines logical structure, but indexes define physical retrieval speed. While the diagram itself does not show indexes, the design decisions impact which indexes are viable.
- Primary Keys: These are clustered in many systems, meaning the data is physically sorted by this key. Choose a primary key that minimizes fragmentation and ensures even distribution.
- Secondary Indexes: Every index consumes write performance. Adding too many indexes slows down insert and update operations. Only index columns that are frequently used in `WHERE`, `JOIN`, or `ORDER BY` clauses.
- Composite Indexes: When multiple columns are queried together, a composite index can be more efficient. The order of columns in the index matters and should match the most common query patterns.
⚖️ Consistency vs Availability in Distributed Schemas
Database theory often discusses the CAP theorem, which suggests a system can only guarantee two out of three properties: Consistency, Availability, and Partition Tolerance. Your ERD design impacts which of these you prioritize.
If you prioritize consistency, you will design with strict foreign keys and ACID transactions. This ensures data integrity but may introduce latency during network partitions. If you prioritize availability, you might relax constraints, allowing temporary inconsistencies. In this case, your ERD should support eventual consistency patterns, such as having a “version” or “status” column to track data state.
🔄 Schema Evolution and Versioning
Software requirements change. The database schema must evolve without causing downtime. In high-traffic systems, you cannot simply drop and recreate tables. Migration strategies must be baked into the ERD design process.
- Backward Compatibility: When adding a column, make it nullable initially. This allows old code to continue functioning while new code populates the data.
- Expandable Types: Avoid fixed-length types where possible. Use variable-length strings or JSON fields for attributes that may change structure over time.
- Logical Deletes: Instead of physically deleting rows, mark them as inactive. This preserves referential integrity for historical data and avoids cascading delete operations that can lock large portions of the table.
🛑 Common Structural Pitfalls
Even experienced architects encounter pitfalls when scaling. Being aware of these common issues can save significant time during the design phase.
1. The N+1 Query Problem
This occurs when an application fetches a list of records and then executes a separate query for each record to fetch related data. In your ERD, identify relationships that are frequently accessed together. If you anticipate fetching related data often, consider denormalizing or creating specific read-model views.
2. Cartesian Products
When joining multiple large tables without proper filtering, the result set can grow exponentially. Ensure your ERD enforces constraints that limit the potential size of join results. Use filters on foreign keys to restrict the scope of relationships.
3. Circular Dependencies
Entities should not depend on each other in a loop. For example, Entity A needs Entity B, and Entity B needs Entity A to initialize. This creates a deadlock scenario during startup or data loading. Break these cycles by introducing an intermediary entity or initializing data in a specific order.
📝 Maintenance and Monitoring
Design is not a one-time event. Once the system is live, you must monitor the health of your data structure. Performance metrics should guide future ERD adjustments.
- Query Analysis: Regularly review slow query logs. If a specific join is consistently slow, revisit the ERD to see if the relationship can be optimized.
- Fragmentation Checks: Over time, deletes and updates can fragment storage. Plan for maintenance windows where indexes are rebuilt or tables are optimized.
- Capacity Planning: As data grows, storage requirements change. Estimate the growth rate of your largest tables and plan for sharding or partitioning before you hit capacity limits.
🛠️ Practical Application: A Scalable Workflow
To implement these principles, follow a structured workflow when creating your diagram.
- Requirement Gathering: Define the read/write ratio and expected traffic patterns.
- Logical Modeling: Create the ERD focusing on business entities and relationships without worrying about physical constraints.
- Physical Modeling: Translate the logical model into a physical schema. Add indexes, define data types, and consider partitioning strategies.
- Review and Validation: Simulate high-load queries against the model. Identify potential bottlenecks in joins or locking.
- Documentation: Document the rationale behind design choices. This helps future developers understand why a specific normalization level was chosen.
🔮 Future-Proofing Your Architecture
Technology evolves rapidly. What works today may not work in five years. Design with flexibility in mind. Avoid tying your schema too closely to a specific storage engine feature that might become deprecated. Focus on the logical relationships and data integrity rules, as these remain constant even as the underlying technology changes.
By following these guidelines, you create a data model that is not only functional for current needs but resilient enough to handle the unpredictability of high-traffic environments. The goal is to build a system that performs consistently, scales horizontally, and remains maintainable over time.

