The shift from traditional on-premises infrastructure to cloud-native environments represents a fundamental change in how data is stored, accessed, and managed. For Database Administrators (DBAs), this transition requires more than just migrating existing schemas. It demands a re-evaluation of Entity-Relationship Diagrams (ERDs) to align with the unique constraints and capabilities of distributed systems. This guide provides a comprehensive look at designing ER diagrams that support scalability, resilience, and performance in modern cloud architectures. 📊
Understanding the Shift in Data Architecture 🔄
Traditional database design often prioritizes strict normalization and centralized control. In contrast, cloud-native architectures emphasize availability, partition tolerance, and horizontal scaling. The core difference lies in the assumption of failure. In a monolithic setup, the database is a single point of failure. In a cloud-native environment, nodes fail frequently, and the system must adapt instantly.
When designing ER diagrams for this environment, DBAs must consider:
- Distributed Consistency: How do relationships hold up when data is split across regions?
- Latency: How does physical distance between data nodes affect query performance?
- Cost: What is the trade-off between storage redundancy and transaction costs?
- Operational Complexity: Can the schema be managed without constant manual intervention?
Ignoring these factors can lead to systems that are difficult to scale or maintain. A well-designed ER diagram acts as the blueprint for data flow, ensuring that the underlying infrastructure can support the business logic without bottlenecks. 🚀
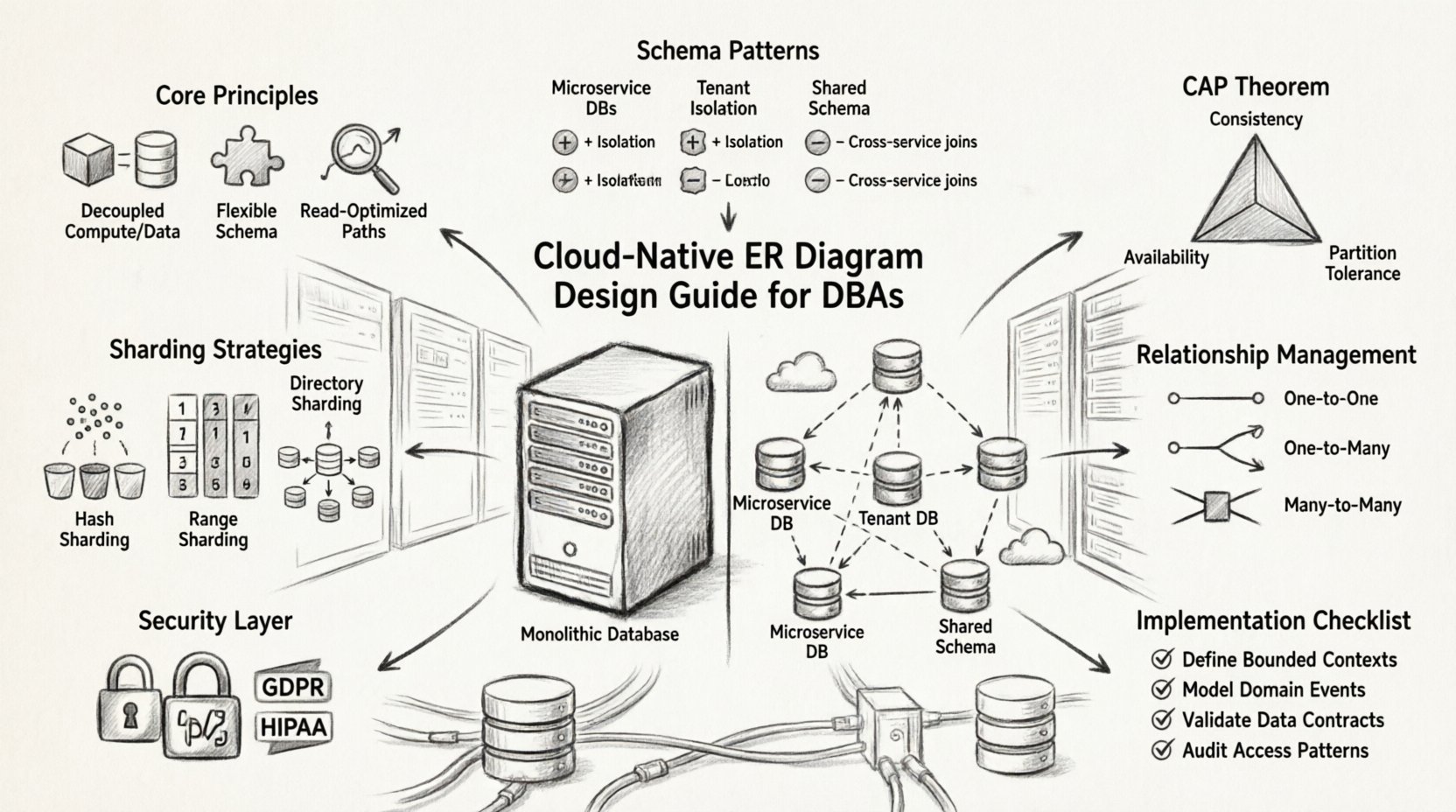
Core Principles of Cloud-Native ERDs ⚙️
Before diving into specific patterns, it is essential to understand the guiding principles that differentiate cloud-native data modeling from traditional approaches.
1. Decoupling Data from Compute
In many legacy systems, the database server and the application server are tightly coupled. Cloud-native design separates these concerns. The ERD should reflect this by minimizing dependencies that require synchronous communication between distinct services.
2. Embracing Schema Flexibility
While SQL databases are rigid, cloud-native environments often utilize polyglot persistence. This means different data types might require different storage models. The ER diagram should visualize logical relationships even if physical implementations vary (e.g., JSON stores alongside relational tables).
3. Optimizing for Read-Heavy Workloads
Cloud applications often serve millions of users simultaneously. The ER design must support efficient read paths, even if it means introducing some redundancy. Denormalization becomes a strategic tool rather than a sin.
Schema Design Patterns for Scalability 📈
Selecting the right schema pattern is critical for performance. Below are common approaches used in distributed systems.
Single Database per Service
Each microservice manages its own database schema. This isolation prevents service failures from cascading. The ER diagram for the overall system becomes a collection of smaller, independent diagrams connected by logical references.
Shared Database with Schema Separation
Multiple services share a single database instance but maintain separate schema namespaces. This reduces infrastructure costs but introduces tight coupling risks. It is generally discouraged for large-scale cloud deployments.
Database per Tenant
In multi-tenant SaaS applications, each customer gets a dedicated database instance. The ERD design must remain consistent across all instances, ensuring that migrations and updates apply uniformly.
Comparison of Schema Patterns
| Pattern | Pros | Cons | Best Use Case |
|---|---|---|---|
| Single Database | Simple joins, ACID compliance | Single point of failure, scaling limits | Monolithic apps, low traffic |
| DB per Service | Independent scaling, fault isolation | Complex transactions, distributed joins | Microservices, high growth |
| DB per Tenant | Data isolation, compliance ease | High infrastructure cost, management overhead | SaaS platforms, regulated industries |
| Shared Schema | Low cost, shared queries | Vendor lock-in, scaling bottlenecks | Internal tools, MVPs |
Managing Relationships Across Services 🔗
In a distributed architecture, foreign keys are not always feasible. Referential integrity must be managed differently. The ER diagram should represent these logical relationships clearly, even if the physical enforcement happens at the application layer or via asynchronous processes.
Types of Relationships
- One-to-One: Often handled by embedding data directly to reduce join latency.
- One-to-Many: Requires careful consideration of how the child records are stored. If the parent moves, do the children move?
- Many-to-Many: Typically implemented via an association table. In cloud environments, this table might need to be sharded independently.
Handling Referential Integrity
Without strict foreign key constraints, data consistency relies on application logic. Strategies include:
- Soft Deletes: Marking records as inactive rather than removing them to preserve history.
- Eventual Consistency: Using event streams to propagate changes across services.
- Compensating Transactions: Rollback logic that handles failures in distributed workflows.
Partitioning and Sharding Strategies 🗂️
As data volume grows, a single database node cannot handle the load. Partitioning (sharding) splits data across multiple nodes. The ER diagram must indicate how data is distributed to avoid hotspots.
Sharding Keys
The choice of sharding key determines how queries are routed. A good key distributes data evenly and aligns with access patterns.
- Hash-Based: Distributes data randomly. Good for uniform access, bad for range queries.
- Range-Based: Splits data by value (e.g., dates or IDs). Good for range queries, risks uneven distribution.
- Directory-Based: Maintains a mapping service to locate data. Adds latency but allows flexible placement.
Impact on ER Diagrams
When designing the ERD, note that:
- Tables that are frequently joined should ideally be co-located to minimize network traffic.
- Global tables (like configuration data) should remain unsharded.
- Indexes must be designed to work within shard boundaries.
Consistency Models and CAP Theorem ⚖️
The CAP theorem states that a distributed system can only guarantee two of three properties: Consistency, Availability, and Partition Tolerance. Cloud-native systems prioritize Partition Tolerance, forcing a choice between Consistency and Availability.
Choosing the Right Model
| Model | Description | ERD Implication |
|---|---|---|
| Strong Consistency | All nodes see the same data at the same time | Requires synchronous writes; limits write throughput |
| Eventual Consistency | Data becomes consistent after a delay | Allows async writes; requires handling stale reads |
| Causal Consistency | Preserves order of causally related operations | Complex tracking of dependencies in the ERD |
For financial applications, strong consistency is often necessary. For social feeds, eventual consistency is acceptable. The ER diagram should annotate which tables require strict ordering and which can tolerate delays.
Indexing for High-Throughput Environments 🏷️
Indexing strategies in the cloud differ from on-premises due to storage costs and network bandwidth. Every index consumes write resources and storage space.
Indexing Best Practices
- Minimize Secondary Indexes: Only index columns used in frequent query predicates.
- Consider Covering Indexes: Include all necessary columns in the index to avoid table lookups.
- Monitor Index Usage: Regularly audit index performance to remove unused structures.
- Partitioned Indexes: Align index structures with the data partitioning strategy.
Global vs. Local Indexes
Global indexes span all shards and can be expensive to maintain. Local indexes reside within a shard and are cheaper. When designing the ERD, specify which indexes are global and which are local to guide the infrastructure team.
Security and Compliance Considerations 🛡️
Data security in the cloud involves encryption, access control, and compliance with regulations like GDPR or HIPAA. The ER diagram should reflect data sensitivity levels.
Data Classification
Tag data entities based on sensitivity:
- Public: No special protection required.
- Internal: Accessible only by employees.
- Restricted: Requires encryption and strict access logging.
Encryption at Rest and in Transit
All sensitive fields should be flagged for encryption. The ERD should not store plaintext sensitive data. Instead, it should reference encrypted columns or tokens.
Compliance and Retention
Some data must be retained for specific periods or deleted entirely. The ER design should include metadata fields for retention policies and audit trails.
Versioning and Schema Evolution 🔄
In cloud-native environments, downtime for schema changes is rare. Migrations must be performed online. The ERD should support versioning strategies.
Backward Compatibility
New schema versions should be backward compatible with the application logic. This allows gradual rollout of changes.
Migration Patterns
- Add Column: Add new fields without changing existing data.
- Double Write: Write to both old and new structures during transition.
- Cutover: Switch read and write traffic once data is migrated.
- Drop Column: Remove unused fields only after confirming no dependencies.
Common Pitfalls to Avoid ⚠️
Even experienced DBAs can stumble when adapting to cloud-native designs. Here are common mistakes.
- Over-Normalization: Too many joins increase latency in distributed systems.
- Ignoring Cold Data: Failing to archive historical data can increase costs and slow down active queries.
- Hardcoded Limits: Setting arbitrary row limits in the application that bypass database constraints.
- Ignoring Latency: Designing queries that assume local data access when data is actually remote.
- Single Points of Failure: Designing a primary database node that, if lost, halts the entire system.
Implementation Checklist ✅
Before deploying a cloud-native database schema, review the following checklist.
| Task | Priority | Status |
|---|---|---|
| Define sharding strategy | High | Not Started |
| Identify read/write patterns | High | Not Started |
| Plan for eventual consistency | Medium | Not Started |
| Design backup and recovery | High | Not Started |
| Set up monitoring alerts | Medium | Not Started |
| Review security policies | High | Not Started |
Maintenance and Monitoring 🔍
A cloud-native database requires continuous monitoring. The ERD is not a static document; it evolves with the application.
Key Metrics
- Query Latency: Track average and p99 response times.
- Connection Pool Utilization: Ensure the application can handle peak loads.
- Storage Growth: Predict future capacity needs.
- Error Rates: Monitor transaction failures and rollbacks.
Automation
Use automated tools to detect schema drift and enforce standards. Manual changes to production schemas should be minimized to reduce human error.
Conclusion 🏁
Designing ER diagrams for cloud-native architectures is a complex task that balances technical constraints with business goals. By focusing on scalability, consistency models, and security, DBAs can build systems that endure growth and change. The key is to treat data modeling as a continuous process rather than a one-time setup. Regular reviews and adherence to best practices ensure that the database remains a reliable foundation for the application. 🌐

