In modern infrastructure, data is not merely stored; it flows. The architecture of your database schema directly influences the stability of your entire distributed ecosystem. When an entity relationship diagram (ERD) is designed without considering the nuances of distributed computing, the result is often brittle. A failure in one node can ripple outward, causing widespread downtime or data corruption. This guide explores how to engineer data models that withstand the inherent volatility of distributed environments.
🧩 Understanding the Link Between Schema and Stability
An ER diagram serves as the blueprint for how data relates to one another. In a monolithic setup, these relationships are managed tightly within a single transactional boundary. However, distributed systems break these boundaries apart. Services operate independently, often owning their own data stores. When you connect these services via shared data models, you introduce coupling.
Resilience in this context means designing schemas that allow parts of the system to fail without bringing the whole down. This requires a shift in perspective: the ERD is no longer just a visualization of structure; it is a contract for behavior. If a foreign key constraint is enforced strictly across a network, a temporary network partition can trigger a cascade of errors. Therefore, the design must account for eventual consistency, latency, and partial failures.
🔑 Key Concepts to Consider
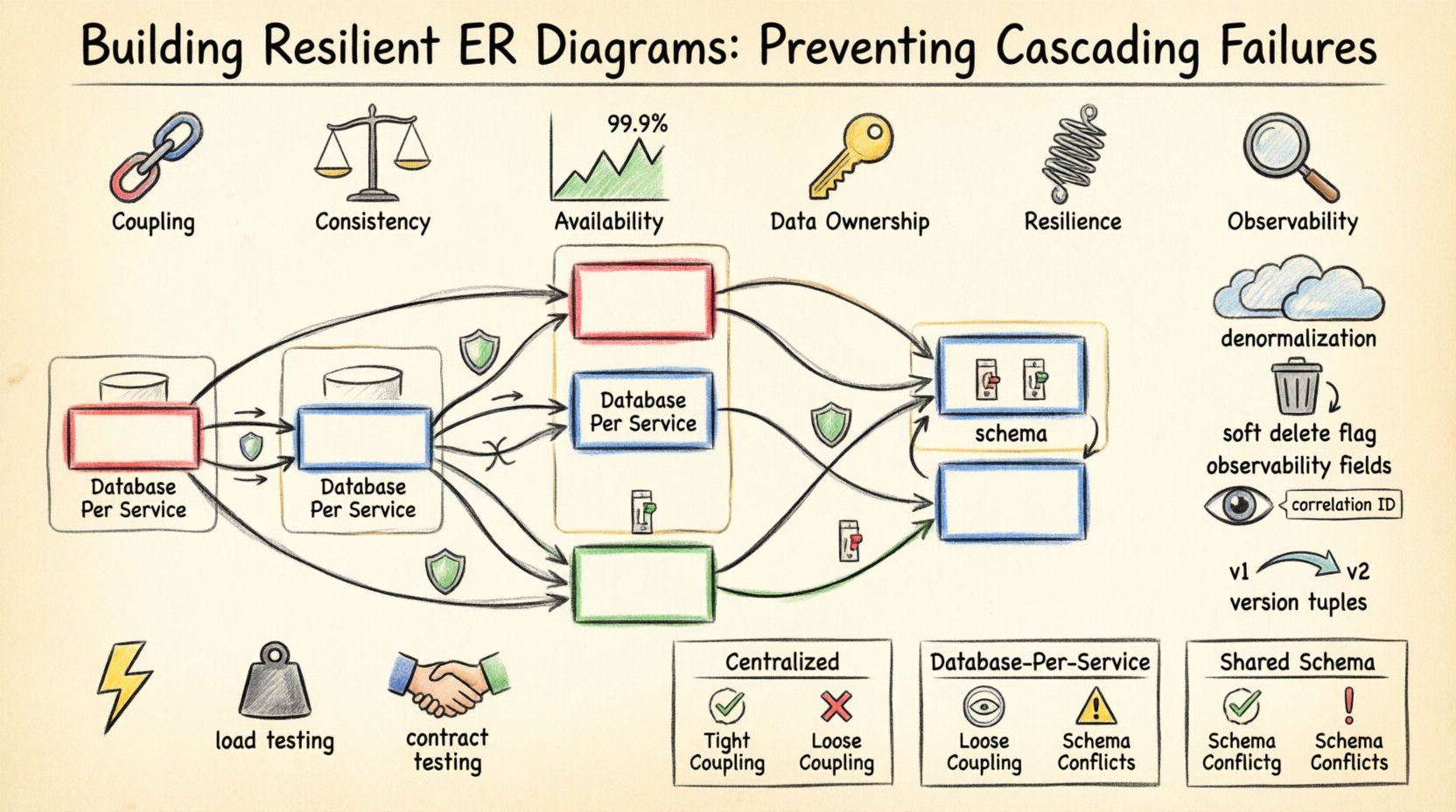
- Coupling: High coupling between entities means changes or failures in one affect the other significantly.
- Consistency: Strong consistency (ACID) ensures data is correct but may reduce availability during network issues.
- Availability: High availability prioritizes uptime, often requiring relaxed consistency rules.
- Data Ownership: Clear boundaries on which service owns which data prevent circular dependencies.
🛡️ Strategies for Relationship Modeling
The way you define relationships between entities is the primary driver of resilience. In a distributed environment, every relationship is a potential network call. Minimizing these calls and handling their failure modes is critical.
1. Avoiding Deep Join Chains
Deeply normalized schemas are excellent for data integrity but can be disastrous for performance in distributed systems. A single query requiring five joins across different services can lead to timeouts and cascading failures. Instead, consider denormalization where it reduces the need for synchronous cross-service lookups.
- Replicate Read Data: Store frequently accessed data redundantly to avoid remote calls.
- Denormalize for Read Paths: Accept write complexity in exchange for read speed and reliability.
- Cache Aggregations: Pre-calculate totals or summaries to reduce real-time processing load.
2. Foreign Keys as Contracts, Not Enforcement
In a single database, a foreign key prevents orphaned records. In a distributed system, enforcing this via database constraints across network boundaries is risky. If Service A is down, Service B cannot validate the relationship, potentially blocking operations.
It is often safer to enforce referential integrity at the application level using validation logic or eventual consistency checks.
- Application-Level Checks: Validate IDs exist before writing, but allow for race conditions.
- Eventual Consistency: Use background jobs to clean up orphans rather than blocking the primary transaction.
- Soft Constraints: Treat foreign keys as logical links rather than hard database locks.
🗃️ Managing Data Consistency Models
Distributed systems must navigate the CAP theorem. Choosing the right consistency model for your entities is vital for preventing data corruption during failures.
| Consistency Model | Use Case | Resilience Impact |
|---|---|---|
| Strong Consistency | Financial transactions, Inventory counts | High reliability, lower availability during partitions |
| Eventual Consistency | User profiles, Social feeds, Logs | High availability, temporary data divergence |
| Read-Your-Writes | Session data, Shopping carts | Balanced user experience with moderate complexity |
When designing your ERD, annotate which entities require strong consistency and which can tolerate eventual updates. This distinction guides how you implement locks, transactions, and replication strategies.
🔄 Handling Schema Evolution
Systems change. Fields are added, types are modified, and relationships shift. In a distributed architecture, you cannot simply alter the schema on all nodes simultaneously. A mismatch between a service and its database version can cause crashes.
Best Practices for Versioning
- Backward Compatibility: New schema versions must be readable by old service versions.
- Deprecation Periods: Keep old fields in the database for extended periods even if they are no longer used.
- Feature Flags: Gate new data structures behind flags to control rollout.
- Expand and Contract: First add the new field (expand), migrate data, then remove the old field (contract).
Documenting these changes in your ERD is essential. Use comments or separate diagrams to show deprecated relationships versus active ones. This prevents engineers from relying on outdated structures.
🛑 Preventing Cascading Failures
A cascading failure occurs when a local failure triggers a chain reaction that impacts the entire system. Data design plays a significant role in containing these events.
1. Circuit Breaking at the Data Layer
Just as you implement circuit breakers in service calls, you should design your data layer to handle timeouts gracefully. If a read query hangs, the system should not wait indefinitely.
- Set Timeouts: Define strict maximum durations for database transactions.
- Fallback Values: If data cannot be retrieved, return a safe default or cached value.
- Rate Limiting: Prevent a single heavy query from consuming all database resources.
2. Isolation of Critical Data
Separate critical data from non-critical data. If a user profile service fails, it should not impact the payment processing service. This separation is reflected in your ERD by distinct schemas or distinct physical databases.
- Database Sharding: Split data across multiple servers to limit blast radius.
- Service Database Perimeter: Each microservice owns its database exclusively.
- Read/Write Separation: Use separate connections for reporting and transactional work.
📉 Soft Deletes vs. Hard Deletes
In distributed systems, a hard delete is risky. If one service deletes a record and another service expects it, the second service will crash or produce errors. Soft deletes provide a safety net.
Instead of removing a row, mark it as deleted with a timestamp or flag. This preserves referential integrity for auditing and reporting while signaling that the data is no longer active.
- Audit Trails: Retain historical data for compliance and debugging.
- Recovery: Accidental deletions can be reversed easily.
- Performance: Avoid the overhead of removing rows from indexes, though it increases storage needs.
🔍 Observability in Data Design
Resilience is not just about prevention; it is about detection. Your ERD should include fields that support monitoring and debugging.
- Correlation IDs: Include a unique ID that travels through all related entities to trace a request.
- Version Tuples: Store version numbers to detect schema drift.
- Status Flags: Explicitly mark records as pending, active, or failed to aid in troubleshooting.
📊 Comparison of Design Patterns
| Pattern | Pros | Cons |
|---|---|---|
| Centralized Database | Simple relationships, easy consistency | Single point of failure, scaling limits |
| Database Per Service | Isolation, independent scaling | Complex transactions, eventual consistency |
| Shared Schema | Easy joins, unified view | Tight coupling, deployment coordination |
🧪 Testing Your Design
Once the ERD is drafted, test it under failure conditions. Do not assume the model will hold up. Simulate network partitions and database outages to see how the relationships behave.
- Chaos Engineering: Inject failures into data nodes to observe recovery.
- Load Testing: Push the system to see if relationships break under stress.
- Contract Testing: Verify that data shapes match between services.
📝 Final Thoughts on Data Architecture
Building resilient systems requires acknowledging that failure is inevitable. Your ER diagram is the first line of defense against chaos. By prioritizing isolation, managing consistency explicitly, and planning for evolution, you create a foundation that supports long-term stability. The goal is not perfection, but graceful degradation. When components falter, the data layer should protect the business logic from collapsing entirely.
Adopt these strategies to ensure your data models contribute to a robust infrastructure. Continuous review of your schema against real-world failure patterns will keep your systems healthy and responsive.

